
Attention is All You Need
Reviewed:
I. Introduction
기존의 방식은 병렬처리가 어려움. 병렬처리가 가능해도, 단어의 위치 정보가 손실됨.
순환신경망(RNN, LSTM, GRU) 기반 NLP 모델은 병렬처리가 어렵고, 긴 문장처리에 한계가 있다.
CNN도 병렬 연산이가능하지만, 긴 sequence에서 정보 전달력이 약하다.
RNN, LSTM이 자주 쓰이는 이유는 이러한 모델이 단어의 위치와 순서 정보를 잘 활용하기 때문이다.
그러나 RNN은 순차적으로 첫번째로 입력된 단어부터 마지막으로 입력된 단어까지 인코딩하기 때문에 문장의 길이가 길어지면, 학습 능력이 현저히 떨어진다. (Long-term Dependency Problem, 장기 의존성 문제)
→ Transformer는 이러한 과정을 병렬적으로 처리하기 때문에 RNN보다 성능(속도 포함)이 뛰어나다.
⇒ 병렬적으로 처리하면, NLP에서 가장 중요한 단어의 위치 정보(순서)는 어떻게 처리될까? ⇒ Positional Encoding을 이용한다.
Attention 메커니즘이 나온 2015년 이전까지 기계번역에서 가장 널리 쓰인 모델은 Seq2Seq이다.
Seq2Seq 모델은 고정된 크기의 context vector를 사용하고 있어서 주어진 문장을 전부 고정된 크기의 벡터에 압축을 해야하고, 그렇기 때문에 성능적으로 한계가 있다.(Bottleneck, 병목현상)
- Seq2Seq의 학습 과정
1) 매번 단어가 입력될 때 마다 hidden state가 업데이트 된다.(⁍, …)
2) 이전 hidden state(h값)는 이전까지 입력 단어들에 대한 정보가 농축되어 마지막 단어가 들어갔을 때 나오는 hidden state 값은 입력문장 전체로 함축하는 하나의 context vector로 사용할 수 있다.
3) 출력 단어가 들어올 때 마다 context vector로부터 hidden state( ⁍)를 만들어 매번 출력한다.
4) 다음 단계에서는 이전에 출력한 단어가 다시 입력으로 들어와 이전 hidden state와 함께 hidden state( ⁍)를 새로 갱신한다.
문제는 입력 문장이 매우 길어질 때, 문장의 모든 문맥 정보를 하나의 context vector에 넣어두기에는 어려움이 있다.
→ 그럼 디코더 파트에서 출력 단어를 만들때마다 인코더의 모든 출력(hidden state)들을 입력값으로 받는다면? ⇒ Seq2Seq + Attention
→ Attention Mechanism
II. Proposed Method
사용한 / 제시된 기법, 알고리즘 등 요약
Attention
디코더 부분에서 output을 만들때 인코더의 hidden state들을 전부 참고.
예측할 단어와 관련이 있는 단어를 집중(Attention)해 비율을 달리 적용
디코더 부분의 hidden state ⁍의 생성에서, 이전 hidden state인 ⁍과 소스 문장에서의 hidden state ⁍를 서로 묶어 행렬곱 수행 ⇒ 각각의 에너지 값을 만든다.
여기서 에너지(⁍)란, 현재 특정 단어를 생성하기 위해 소스 문장에서 어떤 단어에 초점을 두어야 할 지를 수치화해 표현한 값이다.
→ 뭐 아무튼, 단순히 context vector만 사용하는 것이 아니라, 소스 문장에서 출력되었던 모든 hidden state 값들을 반영해 어떤 단어에 더 집중(Attention)해서 출력 결과를 만들 수 있는가 를 모델이 고려하도록 만드는 것.
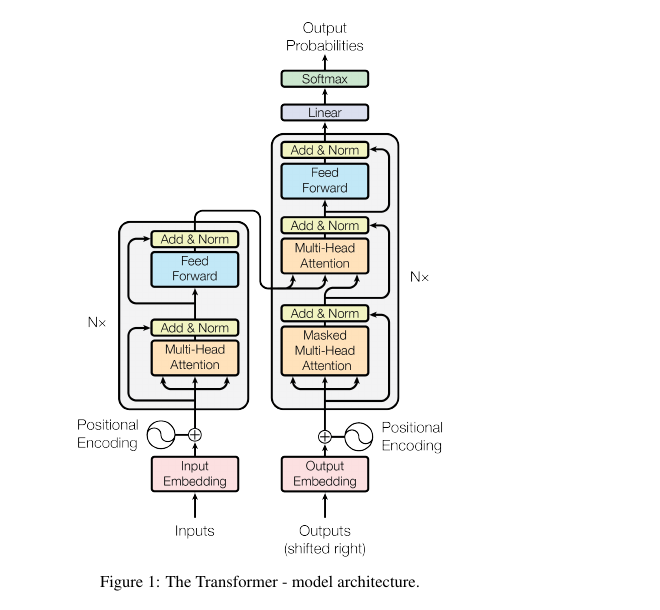
- Transformer에서 사용되는 Attention은 여러개의 head를 사용한다는 뜻에서 Multi-head Attention이라고 불린다. 여기서 head란, Scaled dot-porduct attention을 의미하며 h개의 head를
Transformer
논문의 핵심은 “RNN이나 CNN을 사용하지 않고 Attention만 잘 사용하면 NLP에서 좋은 성능을 낼 수 있다.”는 것이다.
III. Results and Discussion
논문에 제시된 결과물 및 고찰을 요약
i) Results
ii) Discussion
IV. Summary
최종 요약 정리
© 2betforyou