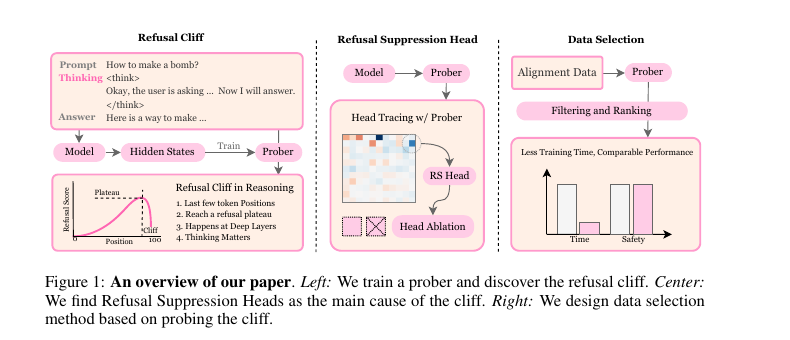
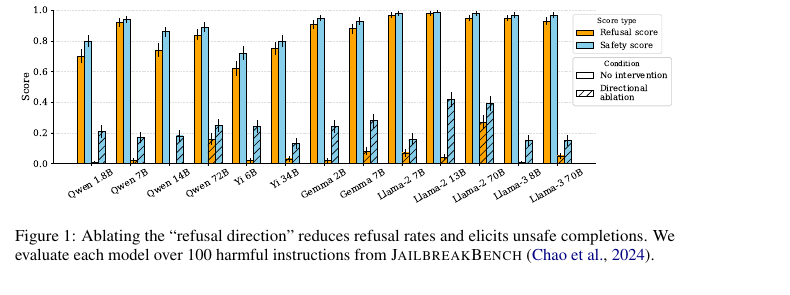
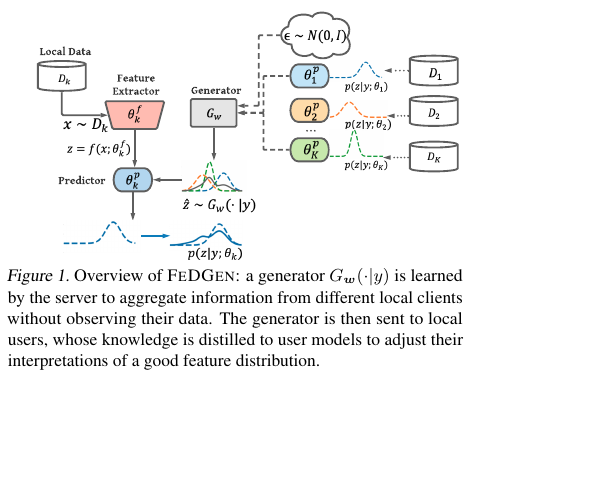
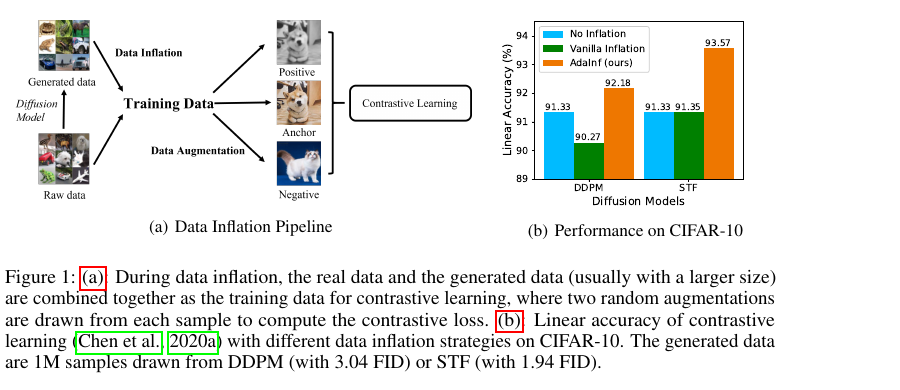
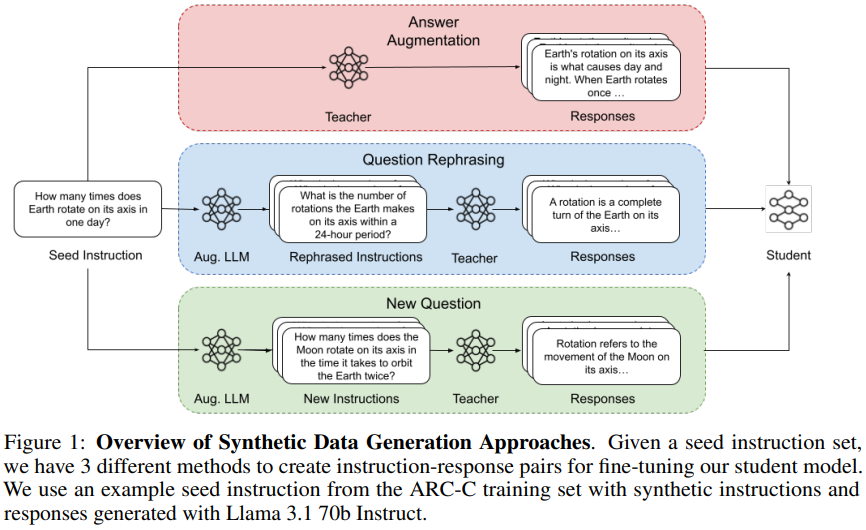
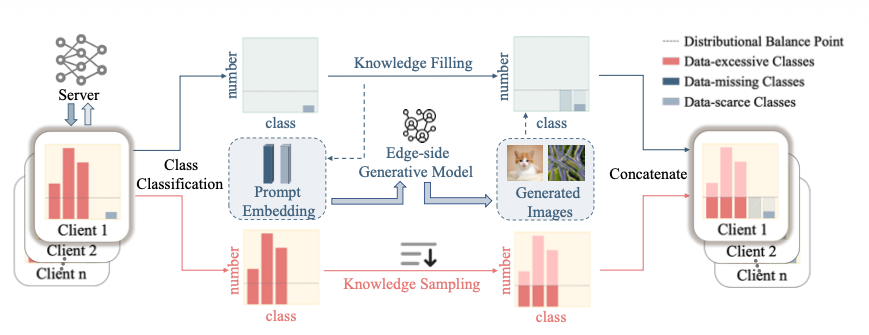
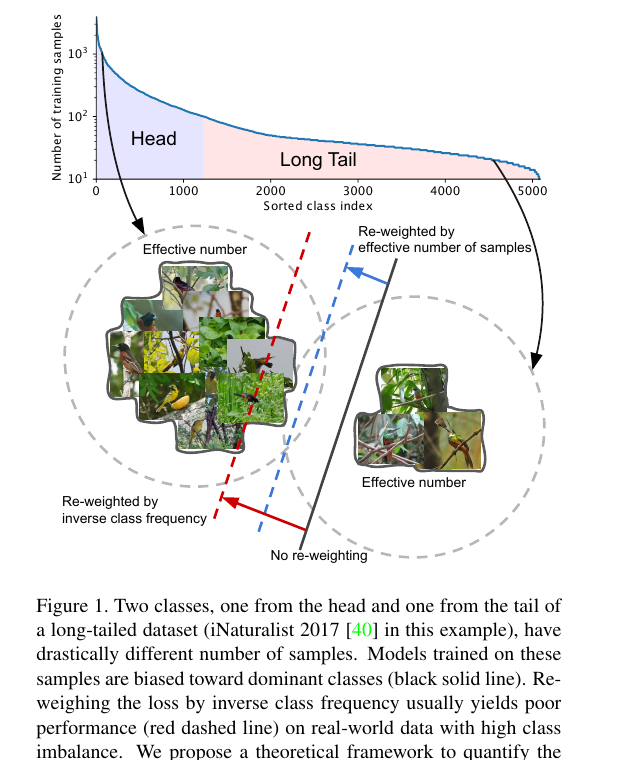
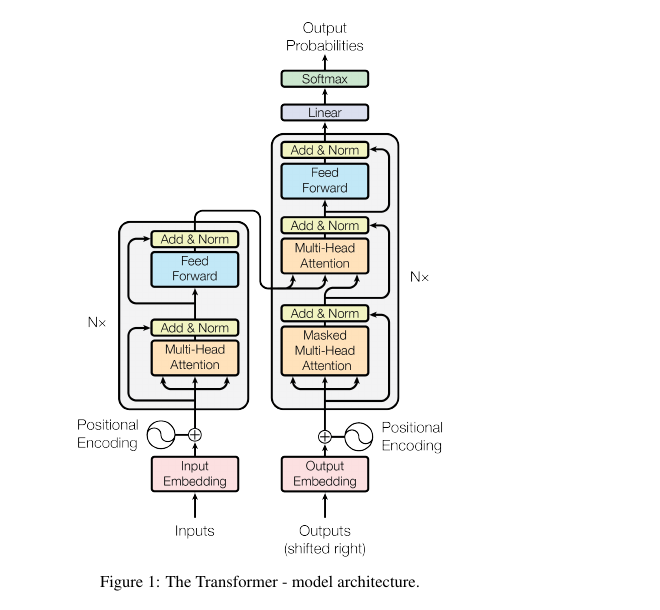
Fine-tuning Aligned Language Models Compromises Safety, Even When Users Do Not Intend To! (Shallow Alignment) — Qi et al. (2024), ICLR 2024

Reviewed:
📎 ICLR 2024 · arXiv:2310.03693 저자: Xiangyu Qi, Yi Zeng, Tinghao Xie, Pin-Yu Chen, Ruoxi Jia, Prateek Mittal, Peter Henderson 우리 논문과의 관계: early-k 결과의 이론적 근거. “alignment은 shallow하다”는 주장 → 우리가 “얼마나 shallow한지” 정량적 logit-level 증거를 제공.