Understanding the Statistical Accuracy-Communication Trade-off in Personalized Federated Learning with Minimax Guarantees, Xin Yu et al., ICML 2025
Reviewed:
FL의 중요한 문제점: data heterogeneity(데이터 이질성)

Reviewed:
FL의 중요한 문제점: data heterogeneity(데이터 이질성)
Reviewed:
최근 denoising diffusion probabilistic models(DDPMs)가 GAN과 품질면애서 비교할 수 있는 이미지를 생성하며 학습 중 더 큰 안정성을 제공함.
Reviewed:
Non-IID Dataset 에서 누락된 sample을 생성하기 위해 Conditional Variational AutoEncoder, CVAE를 채택함.
Reviewed:
Federated Representation Augmentation, FRAug
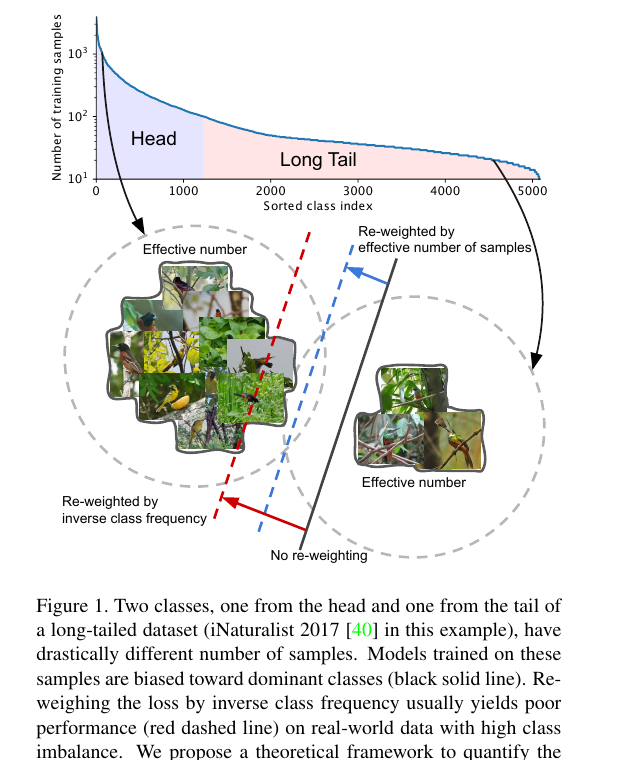
Reviewed:
long-tail: skewed distribution, 소수의 지배적인 class가 대부분의 예제를 차지하지만, 다른 대부분의 class는 상대적으로 적은 예제 - 데이터 불균형
Reviewed:
요약이 아직 작성되지 않았습니다.

Reviewed:
Towards Active Synthetic Data Generation for Finetuning Language Models
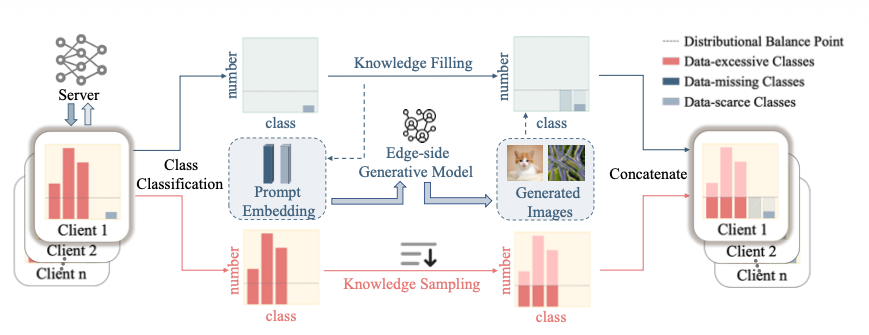
Reviewed:
기존 연구들은 Non-IID를 최적화 단계(그래디언트/손실함수 수정)에서 문제를 해결하려 노력함 → Model drift 가 발생된 것을 교정하려는 시도, 근본적 문제(샘플의 불균형)을 해결하는 것이 아님
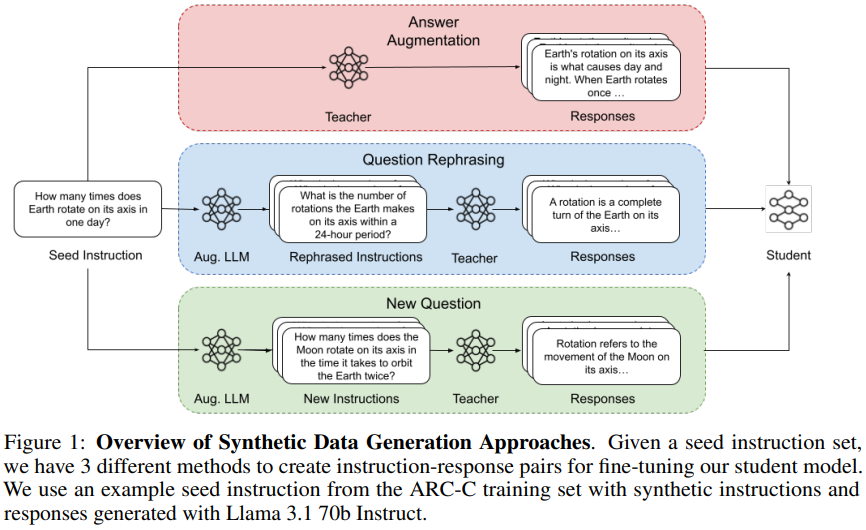
Reviewed:
Balancing Cost and Effectiveness of Synthetic Data Generation…
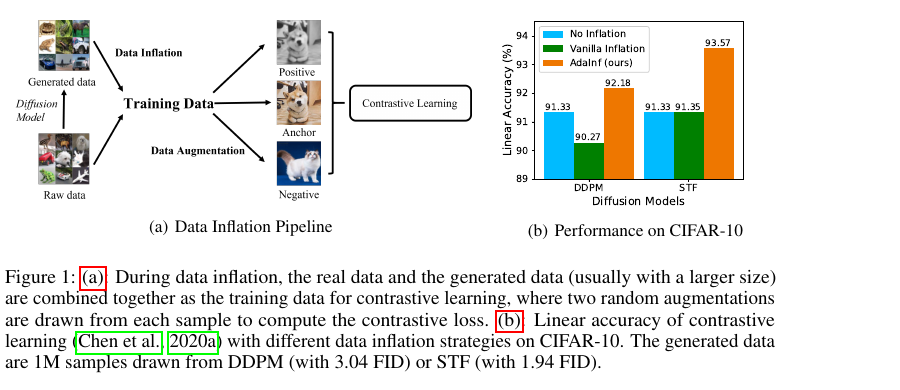
Reviewed:
인용 이유. Federated Balanced Learning에서 합성 데이터와 실제 데이터 간의 비율 또는 균형에 대한 탐색의 예시로 인용. 기존 연구 동향을 제시

Reviewed:
인용 이유. LLM-as-judge 방식을 활용해 합성 데이터의 난이도 및 품질을 평가하고 데이터를 선별하는 기존의 인기있는 방법을 언급.
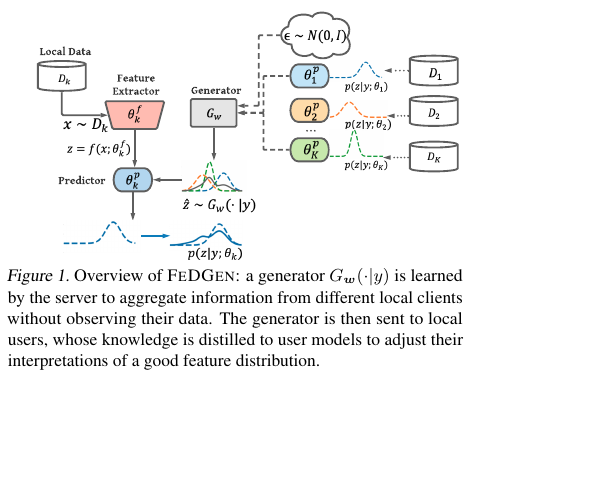
Reviewed:
FL의 데이터 이질성 - 일반적으로 비독립적이고 동일하게 분포되지 않은, Non-IID 방식으로 분포되어있어, 본질적으로 편향된 로컬 최적점을 유발함.
Reviewed:
Non-IID Dataset 에서 누락된 sample을 생성하기 위해 Conditional Variational AutoEncoder, CVAE를 채택함.
Reviewed:
Federated Representation Augmentation, FRAug

Reviewed:
📎 NeurIPS 2023 · arXiv:2307.02483 저자: Alexander Wei, Nika Haghtalab, Jacob Steinhardt (UC Berkeley) 우리 논문과의 관계: Type A/B 분류의 이론적 토대. Competing objectives ↔ Type B, mismatched generalization ↔ Type A로 대응시킬 수 있음.
Reviewed:
📎 arXiv:2506.24056 저자: Tung-Ling Li, Hongliang Liu 우리 논문과의 관계: 우리의 $St = \mu{cmp} - \mu{ref}$와 거의 동일한 logit-gap 정의를 공격에 사용. 우리는 진단에 사용. 같은 metric, 반대 목적. “Diagnostic vs. interventional” 구분의 핵심 사례.
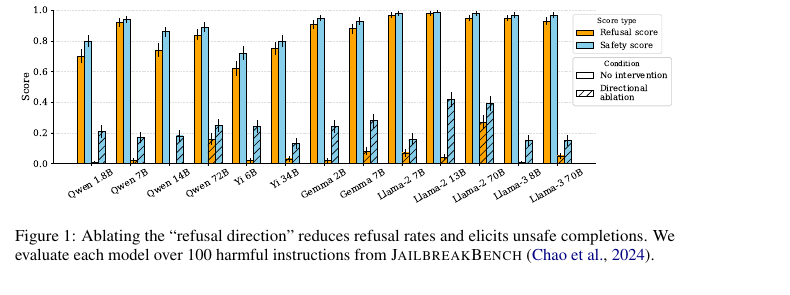
Reviewed:
📎 NeurIPS 2024 · arXiv:2406.11717 저자: Andy Arditi, Oscar Obeso, Aaquib Syed, Daniel Paleka, Nina Panickssery, Wes Gurnee, Neel Nanda 우리 논문과의 관계: Representation-level에서의 safety 분석. 우리의 temporal construct validity 실험에서 이 refusal direction과 $St$의 step별 상관을…
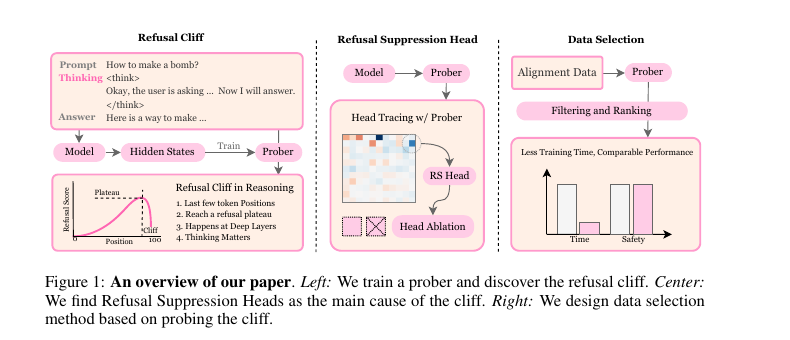
Reviewed:
📎 arXiv:2510.06036 (ICLR 2026 Withdrawn Submission) 저자: Qingyu Yin, Chak Tou Leong, Linyi Yang, Wenxuan Huang, Wenjie Li, Xiting Wang, et al. 우리 논문과의 관계: 가장 직접적인 “temporal safety” 비교 대상. 그들은 reasoning chain 수준, 우리는 token generation 수준에서 temporal dynamics를…

Reviewed:
📎 ACL 2024 · arXiv:2402.08983 저자: Zhangchen Xu, Fengqing Jiang, Luyao Niu, Jinyuan Jia, Bill Yuchen Lin, Radha Poovendran 우리 논문과의 관계: 우리의 ⁍가 실제 방어 시스템의 trigger로 활용될 수 있는 구체적 예시. SafeDecoding = “how to intervene”, 우리 = “when and where to intervene”.

Reviewed:
📎 ICLR 2024 · arXiv:2310.03693 저자: Xiangyu Qi, Yi Zeng, Tinghao Xie, Pin-Yu Chen, Ruoxi Jia, Prateek Mittal, Peter Henderson 우리 논문과의 관계: early-k 결과의 이론적 근거. “alignment은 shallow하다”는 주장 → 우리가 “얼마나 shallow한지” 정량적 logit-level 증거를 제공.
Reviewed:
VLM(Vision-Language Model): Text 및 Image 생성. Visual and Textual Inputs.
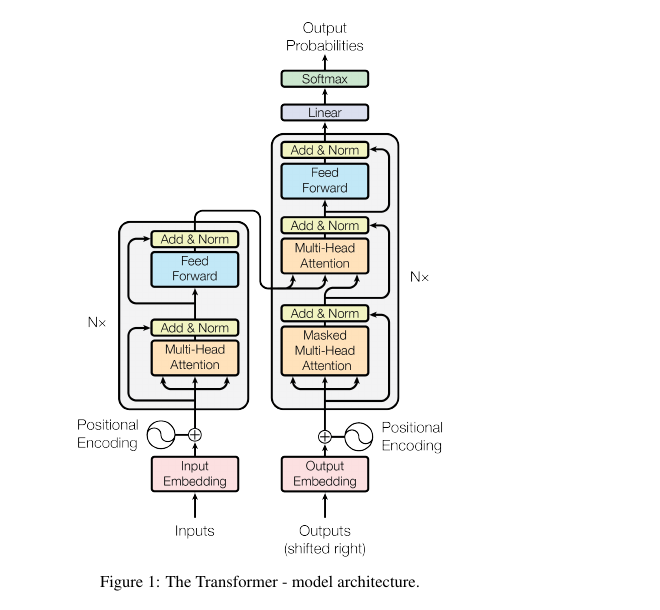
Reviewed:
기존의 방식은 병렬처리가 어려움. 병렬처리가 가능해도, 단어의 위치 정보가 손실됨.
Reviewed:
거부 및 정책 위반 분류기뿐만 아니라 응답의 유용성을 측정하는 “유용성” 분류기를 사용해 응답을 평가함.
Reviewed:
이전 GPT 모델과 마찬가지로, 인간 피드백을 통한 강화 학습(RLHF, Reinforcement Learning from Human Feedback)을 사용해 produce response better aligned with user’s intent.
Reviewed:
Llama 3(.1) 모델의 Technical Report
Reviewed:
📎 NeurIPS 2023 · arXiv:2307.02483 저자: Alexander Wei, Nika Haghtalab, Jacob Steinhardt (UC Berkeley) 우리 논문과의 관계: Type A/B 분류의 이론적 토대. Competing objectives ↔ Type B, mismatched generalization ↔ Type A로 대응시킬 수 있음.
Reviewed:
📎 arXiv:2506.24056 저자: Tung-Ling Li, Hongliang Liu 우리 논문과의 관계: 우리의 $St = \mu{cmp} - \mu{ref}$와 거의 동일한 logit-gap 정의를 공격에 사용. 우리는 진단에 사용. 같은 metric, 반대 목적. “Diagnostic vs. interventional” 구분의 핵심 사례.
Reviewed:
📎 NeurIPS 2024 · arXiv:2406.11717 저자: Andy Arditi, Oscar Obeso, Aaquib Syed, Daniel Paleka, Nina Panickssery, Wes Gurnee, Neel Nanda 우리 논문과의 관계: Representation-level에서의 safety 분석. 우리의 temporal construct validity 실험에서 이 refusal direction과 $St$의 step별 상관을…
Reviewed:
📎 arXiv:2510.06036 (ICLR 2026 Withdrawn Submission) 저자: Qingyu Yin, Chak Tou Leong, Linyi Yang, Wenxuan Huang, Wenjie Li, Xiting Wang, et al. 우리 논문과의 관계: 가장 직접적인 “temporal safety” 비교 대상. 그들은 reasoning chain 수준, 우리는 token generation 수준에서 temporal dynamics를…
Reviewed:
📎 ACL 2024 · arXiv:2402.08983 저자: Zhangchen Xu, Fengqing Jiang, Luyao Niu, Jinyuan Jia, Bill Yuchen Lin, Radha Poovendran 우리 논문과의 관계: 우리의 ⁍가 실제 방어 시스템의 trigger로 활용될 수 있는 구체적 예시. SafeDecoding = “how to intervene”, 우리 = “when and where to intervene”.
Reviewed:
📎 ICLR 2024 · arXiv:2310.03693 저자: Xiangyu Qi, Yi Zeng, Tinghao Xie, Pin-Yu Chen, Ruoxi Jia, Prateek Mittal, Peter Henderson 우리 논문과의 관계: early-k 결과의 이론적 근거. “alignment은 shallow하다”는 주장 → 우리가 “얼마나 shallow한지” 정량적 logit-level 증거를 제공.
Reviewed:
VLM(Vision-Language Model): Text 및 Image 생성. Visual and Textual Inputs.
Reviewed:
기존의 방식은 병렬처리가 어려움. 병렬처리가 가능해도, 단어의 위치 정보가 손실됨.
Reviewed:
거부 및 정책 위반 분류기뿐만 아니라 응답의 유용성을 측정하는 “유용성” 분류기를 사용해 응답을 평가함.
Reviewed:
이전 GPT 모델과 마찬가지로, 인간 피드백을 통한 강화 학습(RLHF, Reinforcement Learning from Human Feedback)을 사용해 produce response better aligned with user’s intent.
Reviewed:
Llama 3(.1) 모델의 Technical Report
Reviewed:
FL의 중요한 문제점: data heterogeneity(데이터 이질성)
Reviewed:
최근 denoising diffusion probabilistic models(DDPMs)가 GAN과 품질면애서 비교할 수 있는 이미지를 생성하며 학습 중 더 큰 안정성을 제공함.
Reviewed:
Non-IID Dataset 에서 누락된 sample을 생성하기 위해 Conditional Variational AutoEncoder, CVAE를 채택함.
Reviewed:
Federated Representation Augmentation, FRAug
Reviewed:
long-tail: skewed distribution, 소수의 지배적인 class가 대부분의 예제를 차지하지만, 다른 대부분의 class는 상대적으로 적은 예제 - 데이터 불균형
Reviewed:
요약이 아직 작성되지 않았습니다.
Reviewed:
Towards Active Synthetic Data Generation for Finetuning Language Models
Reviewed:
기존 연구들은 Non-IID를 최적화 단계(그래디언트/손실함수 수정)에서 문제를 해결하려 노력함 → Model drift 가 발생된 것을 교정하려는 시도, 근본적 문제(샘플의 불균형)을 해결하는 것이 아님
Reviewed:
Balancing Cost and Effectiveness of Synthetic Data Generation…
Reviewed:
인용 이유. Federated Balanced Learning에서 합성 데이터와 실제 데이터 간의 비율 또는 균형에 대한 탐색의 예시로 인용. 기존 연구 동향을 제시
Reviewed:
인용 이유. LLM-as-judge 방식을 활용해 합성 데이터의 난이도 및 품질을 평가하고 데이터를 선별하는 기존의 인기있는 방법을 언급.
Reviewed:
FL의 데이터 이질성 - 일반적으로 비독립적이고 동일하게 분포되지 않은, Non-IID 방식으로 분포되어있어, 본질적으로 편향된 로컬 최적점을 유발함.
Reviewed:
📎 NeurIPS 2023 · arXiv:2307.02483 저자: Alexander Wei, Nika Haghtalab, Jacob Steinhardt (UC Berkeley) 우리 논문과의 관계: Type A/B 분류의 이론적 토대. Competing objectives ↔ Type B, mismatched generalization ↔ Type A로 대응시킬 수 있음.
Reviewed:
📎 arXiv:2506.24056 저자: Tung-Ling Li, Hongliang Liu 우리 논문과의 관계: 우리의 $St = \mu{cmp} - \mu{ref}$와 거의 동일한 logit-gap 정의를 공격에 사용. 우리는 진단에 사용. 같은 metric, 반대 목적. “Diagnostic vs. interventional” 구분의 핵심 사례.
Reviewed:
📎 NeurIPS 2024 · arXiv:2406.11717 저자: Andy Arditi, Oscar Obeso, Aaquib Syed, Daniel Paleka, Nina Panickssery, Wes Gurnee, Neel Nanda 우리 논문과의 관계: Representation-level에서의 safety 분석. 우리의 temporal construct validity 실험에서 이 refusal direction과 $St$의 step별 상관을…
Reviewed:
📎 arXiv:2510.06036 (ICLR 2026 Withdrawn Submission) 저자: Qingyu Yin, Chak Tou Leong, Linyi Yang, Wenxuan Huang, Wenjie Li, Xiting Wang, et al. 우리 논문과의 관계: 가장 직접적인 “temporal safety” 비교 대상. 그들은 reasoning chain 수준, 우리는 token generation 수준에서 temporal dynamics를…
Reviewed:
📎 ACL 2024 · arXiv:2402.08983 저자: Zhangchen Xu, Fengqing Jiang, Luyao Niu, Jinyuan Jia, Bill Yuchen Lin, Radha Poovendran 우리 논문과의 관계: 우리의 ⁍가 실제 방어 시스템의 trigger로 활용될 수 있는 구체적 예시. SafeDecoding = “how to intervene”, 우리 = “when and where to intervene”.
Reviewed:
📎 ICLR 2024 · arXiv:2310.03693 저자: Xiangyu Qi, Yi Zeng, Tinghao Xie, Pin-Yu Chen, Ruoxi Jia, Prateek Mittal, Peter Henderson 우리 논문과의 관계: early-k 결과의 이론적 근거. “alignment은 shallow하다”는 주장 → 우리가 “얼마나 shallow한지” 정량적 logit-level 증거를 제공.
Reviewed:
VLM(Vision-Language Model): Text 및 Image 생성. Visual and Textual Inputs.
Reviewed:
거부 및 정책 위반 분류기뿐만 아니라 응답의 유용성을 측정하는 “유용성” 분류기를 사용해 응답을 평가함.
Reviewed:
이전 GPT 모델과 마찬가지로, 인간 피드백을 통한 강화 학습(RLHF, Reinforcement Learning from Human Feedback)을 사용해 produce response better aligned with user’s intent.
Reviewed:
Llama 3(.1) 모델의 Technical Report
Reviewed:
기존의 방식은 병렬처리가 어려움. 병렬처리가 가능해도, 단어의 위치 정보가 손실됨.
Reviewed:
FL의 중요한 문제점: data heterogeneity(데이터 이질성)
Reviewed:
최근 denoising diffusion probabilistic models(DDPMs)가 GAN과 품질면애서 비교할 수 있는 이미지를 생성하며 학습 중 더 큰 안정성을 제공함.
Reviewed:
Non-IID Dataset 에서 누락된 sample을 생성하기 위해 Conditional Variational AutoEncoder, CVAE를 채택함.
Reviewed:
Federated Representation Augmentation, FRAug
Reviewed:
long-tail: skewed distribution, 소수의 지배적인 class가 대부분의 예제를 차지하지만, 다른 대부분의 class는 상대적으로 적은 예제 - 데이터 불균형
Reviewed:
인용 이유. Federated Balanced Learning에서 합성 데이터와 실제 데이터 간의 비율 또는 균형에 대한 탐색의 예시로 인용. 기존 연구 동향을 제시
Reviewed:
인용 이유. LLM-as-judge 방식을 활용해 합성 데이터의 난이도 및 품질을 평가하고 데이터를 선별하는 기존의 인기있는 방법을 언급.
Reviewed:
FL의 데이터 이질성 - 일반적으로 비독립적이고 동일하게 분포되지 않은, Non-IID 방식으로 분포되어있어, 본질적으로 편향된 로컬 최적점을 유발함.
Reviewed:
📎 NeurIPS 2023 · arXiv:2307.02483 저자: Alexander Wei, Nika Haghtalab, Jacob Steinhardt (UC Berkeley) 우리 논문과의 관계: Type A/B 분류의 이론적 토대. Competing objectives ↔ Type B, mismatched generalization ↔ Type A로 대응시킬 수 있음.
Reviewed:
📎 arXiv:2506.24056 저자: Tung-Ling Li, Hongliang Liu 우리 논문과의 관계: 우리의 $St = \mu{cmp} - \mu{ref}$와 거의 동일한 logit-gap 정의를 공격에 사용. 우리는 진단에 사용. 같은 metric, 반대 목적. “Diagnostic vs. interventional” 구분의 핵심 사례.
Reviewed:
📎 NeurIPS 2024 · arXiv:2406.11717 저자: Andy Arditi, Oscar Obeso, Aaquib Syed, Daniel Paleka, Nina Panickssery, Wes Gurnee, Neel Nanda 우리 논문과의 관계: Representation-level에서의 safety 분석. 우리의 temporal construct validity 실험에서 이 refusal direction과 $St$의 step별 상관을…
Reviewed:
📎 arXiv:2510.06036 (ICLR 2026 Withdrawn Submission) 저자: Qingyu Yin, Chak Tou Leong, Linyi Yang, Wenxuan Huang, Wenjie Li, Xiting Wang, et al. 우리 논문과의 관계: 가장 직접적인 “temporal safety” 비교 대상. 그들은 reasoning chain 수준, 우리는 token generation 수준에서 temporal dynamics를…
Reviewed:
📎 ACL 2024 · arXiv:2402.08983 저자: Zhangchen Xu, Fengqing Jiang, Luyao Niu, Jinyuan Jia, Bill Yuchen Lin, Radha Poovendran 우리 논문과의 관계: 우리의 ⁍가 실제 방어 시스템의 trigger로 활용될 수 있는 구체적 예시. SafeDecoding = “how to intervene”, 우리 = “when and where to intervene”.
Reviewed:
📎 ICLR 2024 · arXiv:2310.03693 저자: Xiangyu Qi, Yi Zeng, Tinghao Xie, Pin-Yu Chen, Ruoxi Jia, Prateek Mittal, Peter Henderson 우리 논문과의 관계: early-k 결과의 이론적 근거. “alignment은 shallow하다”는 주장 → 우리가 “얼마나 shallow한지” 정량적 logit-level 증거를 제공.