
Class-Balanced Loss Based on Effective Number of Samples, CVPR 2019
Reviewed:
https://arxiv.org/abs/1901.05555
I. Introduction
논문 Introduction 요약
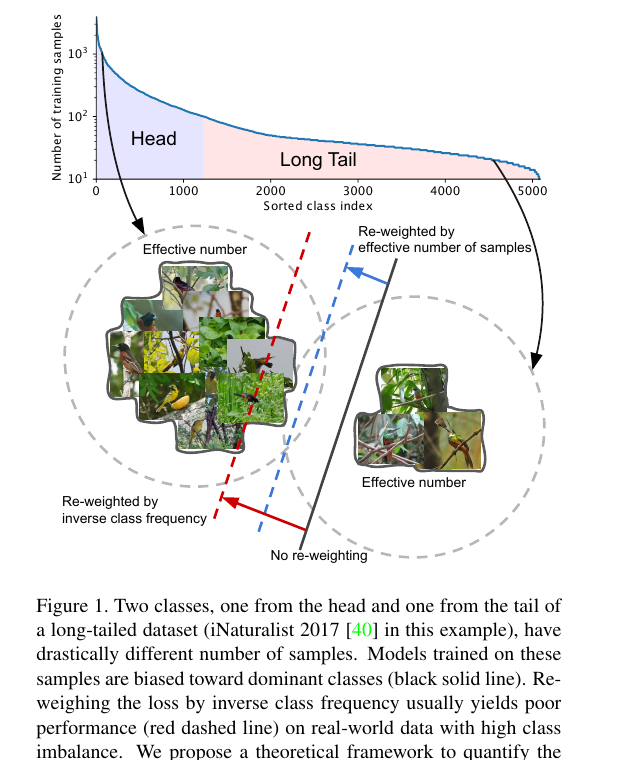
long-tail: skewed distribution, 소수의 지배적인 class가 대부분의 예제를 차지하지만, 다른 대부분의 class는 상대적으로 적은 예제 - 데이터 불균형
long-tail 해결법: 1) re-sampling 2) cost-sensitive re-weighting
- resampling: 소수 class에 대한 oversampling - minority class는 늘리고, 다수 class에 대한 undersampling - majority class는 줄이거나 그대로 두는 방식
- 장점: model 구조나 loss를 바꿀 필요 없음. 구현이 간단함
- 단점:
1) oversampling: 동일 sample을 반복 → overfitting + synthetic data quality에 크게 의존해야함
2) undersampling: 유용한 정보가 손실될 수 있으며, majority class의 성능 저하
→ 근본적 문제: “모든 sample을 동등한 정보량으로 취급한다”라는 가정. 즉 샘플수만 맞춪다고 해서 정보 불균형이 해소되지 않음. # of samples ⁍ information ← 이게 근본적인 문제임
- sample간 정보 중복과 diminishing returns를 고려하지 못함.
- cost-sensitive re-weighting: 데이터는 그대로 두고, 학습 과정에서 class의 중요도를 조절하자
- loss function에 class-wise weight를 부여. minority class의 error 를 더 크게 반영
대표적인 방법들: class-weighted cross entropy, cost-sensitive learning, focal loss - 어려운 sample에 더 큰 weight를 부여
장점: 데이터 조작 없이 imbalance에 대응. overfitting 위험이 상대적으로 낮음
- 단점: 대부분의 기존 방법은 ⁍ 처럼 sample 수에 단순 역수로 weight를 설정함
1) 샘플 수 증가 ⁍ 정보량 증가. 근데 이게 같다고 가정한게 문제임.
2) sample이 많아질수록 중복이 증가하고 marginal benefit이 감소함
→ 결과적으로 minority class에 과도한 weight ⇒ 학습 불안정 / 과보정 → balance가 역전되어 깨짐..
- 그래서 class 빈도의 제곱근에 반비례하게 바꿈(경험적). 이게 smoothed version
Challange:
데이터 규모와 class 불균형 정도가 극단적인 다른 다양한 데이터셋에도 공통으로 적용 가능한, 더 나은 class-balanced loss function은 어떻게 설계할 수 있을까?
- 데이터가 많으면 좋음(직관) → 근데 이제, 데이터간에 정보 중복이 존재하기때문에 # sample 이 중가하며 model이 data로 부터 추출할 수 있는 marginal benefit(한계이익)은 감소함.
**⇒ 데이터 중복을 특성화하고 모델 및 loss와 무관한 방식으로 effective number of samples(유효 샘플수)를 계산하기 위한 framework를 제안함. **
이 유효 샘플수에 반비례하는 class-balanced re-weighting 항이 loss function에 추가됨.
II. Proposed Method
사용한 / 제시된 기법, 알고리즘 등 요약
3. Effective Number of Samples
기존 class weighting / sampling 접근은 암묵적으로 1) 각 sample은 서로 독립적인 점이며 2) sample 하나가 추가되면 정보가 정확히 1 증가 한다고 가정함(⁍, 비례)
근데 이제, long-tailed data에서는, 같은 class 내 sample 들이 매우 유사하며, 많이 모일수록 중복 정보가 급증.
⇒ 그래서 논문은, 각 sample에 “데이터 공간에서 작은 region”을 덮는다고 생각함.
같은 class의 samples가 늘어나면, 처음에는 새로운 영역을 많이 덮지만, 나중에는 이미 덮인 영역을 또 덮는다.
⇒ 샘플 추가의 한계 효용(marginal utility)이 감소한다.
3.1 Data Sampling as Random Covering
Random covering problem: 큰 집합을 무작위로 선택된 작은 집합들로 채우는 문제
에서 영감을 받음
- ⁍: 전체 데이터 공간인줄 알았지만,** 클래스 별 실제로 몇 개의 ‘독립적인 정보 단위’를 관측했는가?** 임. 즉, 관측된 샘플들이 제공하는 ‘중복을 제거한 유효 정보량의 총합’
- 왜냐하면,
⁍: ⁍의 부피 ⁍
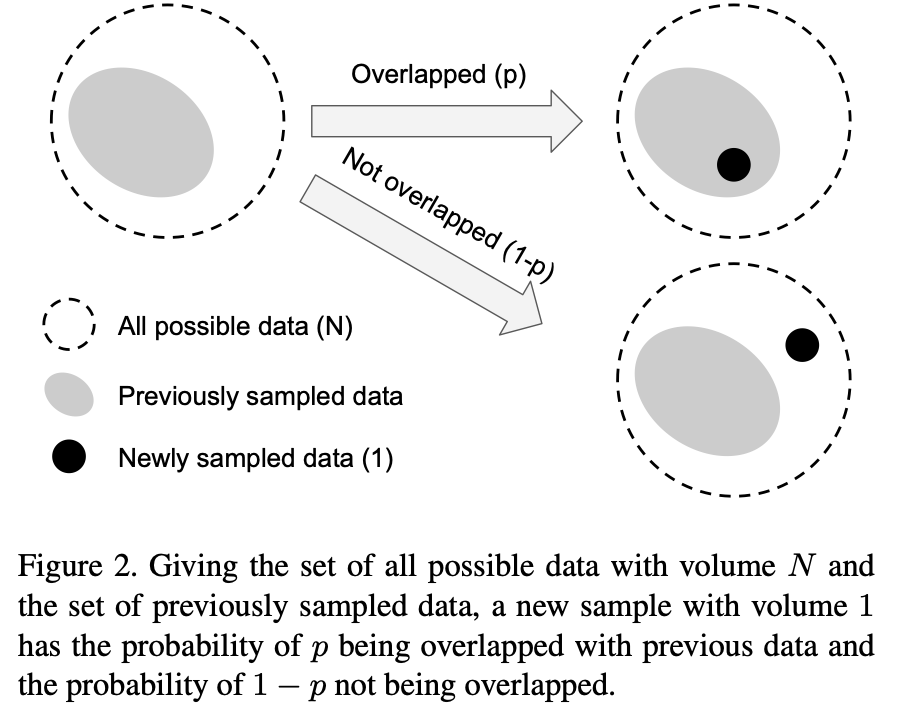
샘플링 과정: 데이터를 수집하는 과정은 전체 부피 ⁍인 공간에 부피가 1인 sample(부분집합)을 무작위로 던져서 공간을 채우는 것과 같음.
Expected Volume, 기대부피: samples에 의해 가려진 실제 면적의 평균값
S를 어떻게 정의했냐?
해당하는 데이터셋의 전체 학습 데이터 분포를 기준으로 클래스별 S(effective number of samples)를 계산
- ⁍⁍
**Definition 1(Effective Number). **
effective number of samples(유효샘플수)는 samples의 expected volume(기대부피)임.
samples의 기대부피를 계산하는건 어려움 - sample의 모양과 feature space의 dimension에 따라 달라짐.
→ 부분적인 중첩 상황을 제외함.
→ 그러면, 새로 sampling 된 데이터는
⁍ 의 확률로 이전 sampling된 데이터 집합 내부에 완전히 포함됨.
⁍ 의 확률로 완전히 외부에 포함됨
- sampling된 데이터 포인트 수가 증가할수록 확률 ⁍는 더 높아짐.
⇒ **어떤 class에서 데이터 포인트를 많이 사용할수록, 추가로 얻는 정보량(이득)은 점점 줄어들 것이다**.를 수식적으로 포착할거임. **
실제 데이터 간의 내재적 유사성 때문에, sample 수가 증가함에따라 새로 추가된 sample이 기존 sample의 (거의) 복제본일거임.
또한 CNN은 무작위 crop, re-scaling(크기조정), 수평/수직 flip(뒤집기) 과 같은 간단한 변환이 입력 데이터에 적용되는 과도한 데이터 증강으로 훈련됨.
⇒ 이 경우도 원본 예제와 동일한 것으로 간주됨(정보적인 관점에서) ⇒ 생성된 이미지도 그럴까?
데이터 증강이 강할수록 ⁍의 크기는 감소할 것으로 추정됨 ⇒ 이 ⁍은 서로 다른 고유한 prototype 수임. data 수가 아님.
⇒ 이런 증강은 정보적으로 거의 동일하다. ⇒ **원본 sample 하나는 그 주변의 작은 의미적으로 동일한 region을 대표한다. **
3.2 수학
⁍: 유효 샘플수, effective number of samples. 여기서 ⁍은 sample 수.
명제 1(Effective Number).
⁍
→ Effective number of samples는 ⁍의 지수함수임. hyperparameter ⁍은 ⁍이 증가함에 따라 ⁍이 얼마나 증가하는지를 제어함.
⇒ ⁍로 표현 가능.
이는 ⁍번째 sample이 유효 샘플수에 ⁍을 기여함을 의미함.
→ effective number 라는 총합에 이 sample이 얼만큼의 유효정보량을 더해주는가?
→ ⁍**번째 sample이 ‘정보량 관점에서’ 얼마나 기여하냐? **를 의미함.
class에 대한 모든 가능한 데이터의 총 기대 부피 ⁍은 다음과 같이 계산될 수 있음:
⁍ (이는 명제1에서 ⁍의 정의와 일치)
**Implication 1(Asymptotic Properties). **
⁍ if ⁍. ⁍ as ⁍
⁍이면, ⁍
⁍이면, ⁍, ⁍라 하면, 로피탈 어쩌고…
⁍