
Data-Free Knowledge Distillation for Heterogeneous Federated Learning, ICML 2021 PMLR 139
Reviewed:
https://arxiv.org/pdf/2105.10056
I. Introduction
논문 Introduction 요약
FL의 데이터 이질성 - 일반적으로 비독립적이고 동일하게 분포되지 않은, Non-IID 방식으로 분포되어있어, 본질적으로 편향된 로컬 최적점을 유발함.
그래서 FedAvg 와 같은 요소별 평균(element-wise average)을 수행하는 것은 별로임. 이상적인 전역모델로 유도하지 못할 수 있음.
이질성 해결을 위한 두 상호보완적인 관점:
- local 학습을 안정화 시키자
- 파라미터 공간에서 global model 로부터 local model deviation(편차)를 규제해 local 학습을 안정화.
업데이트 폭을 줄여 수렴/안정성 개선
→ 이건 client 모델 간의 기본 지식을 완전히 활용하지 못할 수 있음.
client 모델이 서로 다른 것은 노이즈가 아니라 각자의 데이터 구조적 차이를 반영할 수 있는데, 그걸 전역모델에 묶어두면 별로임.
- 모델 aggregation을 더 잘하자
- parameter 평균 말고, 더 똑똑하게 합쳐서 전역 모델을 만들자. 그중 대표가 Knowledge Distillation, KD임.
→ 이건 local model들이 교사 앙상블, server의 global model 이 학생 모델. 학생모델이 교사들의 예측을 따라가게 학습.
- 문제 1)
근데 KD를 하려면 input ⁍가 필요한데, 서버가 프록시 데이터셋(라벨 없는 데이터라도) 갖고있어야 함.
즉 라벨은 없어도 되지만, 데이터가 있긴 해야함.
⇒ 서버가 적절한 프록시 데이터를 공학적으로 준비해야 하는데,
의료, 금융, 개인정보 환경에서는 서버에 데이터가 없거나, 있어도 분포가 안맞거나, 만들기 비싸거나, 법/정책상 저장이 불가함.
그래서 대부분은 실제 응용이 불가능함.
- 문제 2)
global 모델만 고치면, local 모델의 이질성은 그대로임.
KD는 보통 global model(학생)만 정제함. 그러고 각 client의 local model들이 가진 편향은 그대로 남음.
그러면, 교사 앙상블(local model들) 자체가 품질이 낮으면, global 모델이 배우는 지식의 품질이 별로일 수 있음.
특히 각 client 데이터의 표본이 적으면, local 모델이 편향됨. → 편향된 교사 → 좋은 지식이 나오기 힘듦.
FedGen(Federated Distillation via Generative Learning)이라고 하는 데이터 없는 지식 증류 접근법을 제안.
FedGen은 client model 의 prediction rule만으로 생성기를 학습함.
predicition rule은 각 client model이 입력을 받으면 어떤 확률/로짓을 내는지(⁍)임.
client model들의 예측 행태만 가지고 generator를 학습함.
이 모델은 라벨을 주면, 여러 client 예측과 일치하는 특징 벡터를 생성함. - 그 특징 벡터를 각 client 모델(교사)에게 넣어도 다수의 client가 동의하도록 생성됨.
- 즉, 목표라벨 ⁍를 주면, 생성기가 특징 공간에서 샘플을 생성
그 generator 를 다시 모든 client 에 내려보내서, local 학습을 돕는다.
- 각 client 는 자기 데이터로 학습 + generator 에서 뽑은 특징 샘플로 학습 ← 이게 escort: local 학습 옆에서 가이드/정규화 해주는 역할
생성 샘플이 곧 다른 사용자들로부터 증류된 지식이다.
입력 공간보다 훨씬 적은 차원의 잠재공간을 이용해 오버헤드를 줄임.
FedGen의 장점
모델 평균화 이후 완화되었던, 사라졌던 client 지식을 외부 데이터 없이 추출
추출된 지식을 사용해 local 모델 업데이트를 직접 규제함. - 이러한 지식이 local model에 inductive bias(귀납적 편향 - local model이 학습할 때 갖는 기본적인 선호/가정)을 부여해 Non-IID 데이터 분포에도 더 나은 일반화 성능을 이끌어냄.
전체 파라미터 공유가 어려운 더 빡센 FL에서도 됨. - 통신량이 너무 크거나 프라이버시 때문에 전체 파라미터를 못올리는 경우에도 가능. 왜? FedGen은 지식을 추출하는데 local model의 prediction layer(마지막 분류/예측 헤드)만 필요하다고 주장 - 예측층만으로 동작 가능
II. Proposed Method
사용한 / 제시된 기법, 알고리즘 등 요약
표기법 및 도메인 정리
⁍: 입력 데이터 공간. ⁍ 차원의 데이터
⁍: 잠재 특징 공간. 데이터에서 추출된 특징들이 위치하는 저차원 공간 ⁍
⁍: 출력 공간(라벨)
도메인 ⁍:
⁍
⁍: 입력 공간 ⁍상의 데이터 분포
⁍: 정답 라벨링 함수(ground-truth labeling func)
모델 구조(⁍):
- 모델 parameter ⁍는 두 부분으로 나뉨. ⁍
특징 추출기 ⁍: ⁍에 의해 파라미터화 됨. 입력 ⁍를 잠재공간의 특징 ⁍로 변환 ⁍
예측기 ⁍: ⁍에 의해 파라미터화 됨. 특징 ⁍를 받아 라벨에 대한 확률 분포 ⁍를 출력 ⁍
FL의 목적함수(Equation 1)
모든 사용자의 작업 ⁍에 대해 손실을 최소화 하는 전역 모델 ⁍를 배우는 것.
⁍
여기서 ⁍: 모든 사용자 task ⁍집합 ⁍에 대한 기댓값(평균)을 구함.
⁍. 손실은 이렇게 계산됨..
여기서 ⁍는 실제 정답 값이며, ⁍는 모델 최종 예측값, ⁍은 cross entropy 등의 손실 함수
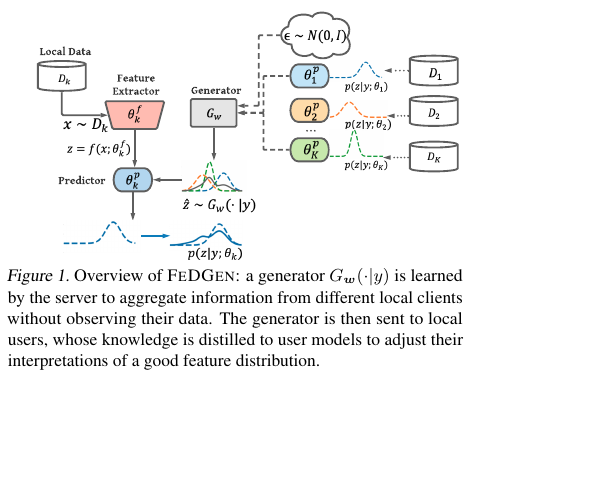
FedGen - Knowledge Extraction
기존 FL로는 서버가 전체 데이터 분포의 모습(전역 관점)을 직접 알기 어려운데, 우리는 사용자 모델들의 예측에서 그 전역 분포에 대한 지식을 뽑아내고,
그 지식을 로컬 모델에 증류해 로컬 학습이 더 잘되도록 유도한다.
서버는 정답 라벨⁍이 주어졌을 때, 그에 맞는 특징 ⁍를 생성하는 조건부 분포 ⁍를 찾고자 함. - 이상적인 지식 추출
⁍
여기서 ⁍는 전체 라벨 분포⁍에서 샘플링된 ⁍에 대한 기댓값. ⁍는 생성기 ⁍가 만든 데이터 ⁍에 대한 기댓값. ⁍는 생성된 데이터 ⁍가 실제 정답 ⁍로 분류될 확률(로그우도)
실제 상황에서는 데이터 공간 ⁍가 너무 고차원이고 개인정보 유출 위험이 있음.
그래서 FedGen은 더 압축된 잠재공간 ⁍에서 예측한 결과의 평균을 사용해 이를 근사함.
근데 이제, 실제 정답 분포 ⁍를 알 수 없기 때문에, 서버는 여러 client model⁍이 예측한 결과의 평균을 사용해 이를 근사함. - Ensemble wisdom, 집단 지성
⇒ server는 모든 local model의 예측 결과가 일관되게 정답 ⁍를 가리키도록 Generator⁍를 학습함.
여기서 ⁍는 출력 로짓, ⁍는 활성화 함수
→ 임의의 정답 ⁍가 주어지면, Equation 4를 최적화 하는 것은 사용자 모델의 예측기 모듈 ⁍에 대한 접근을 필요로 함.
FedGen - Knowledge Distillation
Generator 배포: 서버는 학습된 Generator ⁍를 모든 local users에게 브로드캐스트 함.
Data Augmentation: 각 사용자는 실제 데이터가 부족하더라도 ⁍로부터 가상의 feature representation(특징 표현) ⁍를 샘플링해 학습 데이터처럼 쓸 수 있음