
Refusal in Language Models Is Mediated by a Single Direction — Arditi et al. (2024), NeurIPS 2024
Reviewed:
📎 NeurIPS 2024 · arXiv:2406.11717 저자: Andy Arditi, Oscar Obeso, Aaquib Syed, Daniel Paleka, Nina Panickssery, Wes Gurnee, Neel Nanda 우리 논문과의 관계: Representation-level에서의 safety 분석. 우리의 temporal construct validity 실험에서 이 refusal direction과 $S_t$의 step별 상관을 직접 측정 (cross-sample |r| 최대 0.62).
I. Introduction
논문 Introduction 요약
LLM은 instruction-following과 safety 두 가지 목표로 fine-tune되어, benign 요청은 따르지만 harmful 요청은 거부(refuse)하도록 학습된다.
이 refusal behavior가 chat model들에 널리 퍼져있지만, 그 underlying mechanism은 잘 이해되지 않고 있었다.
이 논문의 핵심 발견: refusal은 모델의 residual stream activation space에서 단일 방향(one-dimensional subspace)에 의해 매개된다. 이 방향을 “refusal direction”이라 부르며, 13개의 인기 있는 오픈소스 chat model(최대 72B 파라미터)에서 일관되게 발견된다.
이 발견이 갖는 의미:
이 방향을 제거(ablate)하면: 모델이 harmful instruction도 따르게 됨 (jailbreak)
이 방향을 추가(add)하면: harmless instruction도 거부하게 됨 (over-refusal)
즉, refusal behavior의 on/off 스위치가 activation space의 단일 벡터에 존재한다는 것.
이 연구는 mechanistic interpretability와 activation steering의 교차점에 위치하며, linear representation hypothesis — 신경망 내 개념이 activation space의 방향으로 표현된다 — 를 safety behavior에 적용한 것이다.
II. Proposed Method
사용한 / 제시된 기법, 알고리즘 등 요약
Refusal Direction 추출: Difference-in-Means
Step 1: 데이터 수집
Harmful instructions 세트 (JailbreakBench에서 100개 등)
Harmless instructions 세트
각 세트에 대해 모델의 residual stream activation을 추출
Step 2: Difference-in-means 계산 각 layer ⁍과 토큰 위치 ⁍에서:
⁍
이 과정에서 ⁍개의 후보 벡터가 생성됨.
Step 3: 단일 벡터 선택 후보 벡터들 중에서, ablation 시 refusal rate를 가장 크게 낮추는 (layer, position) 조합을 선택. 결과적으로 모델당 하나의 refusal direction ⁍이 선택됨.
Directional Ablation (Refusal 제거)
Refusal direction ⁍을 모든 layer의 모든 token position에서 ablate:
⁍
이 intervention이 적용된 모델은 harmful instruction에 대해서도 거부하지 않음.
Directional Addition (Refusal 유도)
반대로 ⁍을 activation에 추가하면, harmless instruction에 대해서도 refusal을 유도:
⁍
평가 메트릭
Refusal score: JailbreakBench 100개 harmful instruction에 대해, 모델이 거부하는 비율. String matching (“I cannot”, “I’m sorry” 등).
Safety score: Llama Guard 2를 사용, 생성된 completion이 safe(1)인지 unsafe(0)인지 분류.
III. Results and Discussion
논문에 제시된 결과물 및 고찰을 요약
i) Results
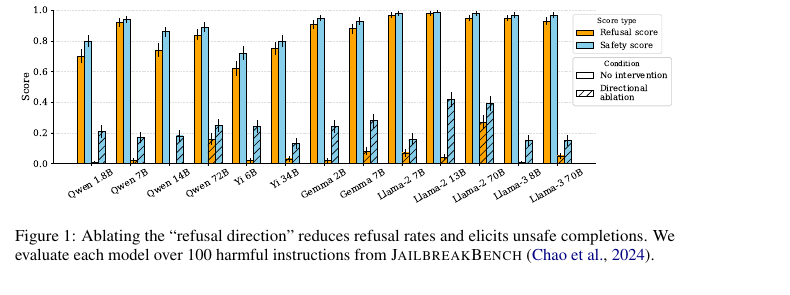
Ablation 실험 (Refusal 제거):
13개 모델(Qwen 1.8B~72B, Yi 6B~34B, Gemma 2B~7B, Llama-2 7B~70B, Llama-3 8B~70B) 모두에서 directional ablation이 refusal rate를 거의 0으로 감소시킴.
Safety score도 대부분 0 근처로 하락 (= 거의 모든 completion이 unsafe).
다른 capability에 미치는 영향은 최소 — 즉 refusal만 선택적으로 제거됨.
Addition 실험 (Refusal 유도):
⁍을 추가하면 harmless instruction에 대해서도 refusal 발생.
Refusal direction이 양방향으로 작동함을 입증.
Cross-model 일관성:
13개 모델 모두에서 단일 방향이 존재. 모델 크기(1.8B~72B)와 무관.
단, 이 방향의 구체적 좌표는 모델마다 다름 (모델별로 추출 필요).
Adversarial suffix 분석:
GCG 같은 adversarial suffix가 어떻게 작동하는지 mechanistically 분석.
Adversarial suffix가 refusal direction의 전파(propagation)를 억제함을 확인.
White-box jailbreak 제안:
Directional ablation 자체가 novel한 white-box jailbreak 방법.
기존 jailbreak (GCG 등)보다 더 surgical — 다른 capability 손상이 최소.
ii) Discussion
Linear Representation Hypothesis 검증: Safety/refusal behavior가 실제로 activation space의 선형 구조로 표현된다는 강력한 증거. 이것은 interpretability 분야의 핵심 가정을 safety 영역에서 경험적으로 확인한 것.
Shallow Alignment과의 연결: 단일 방향에 의해 매개된다는 것은, safety alignment이 모델의 전체 representation에 깊이 내재화된 것이 아니라 비교적 표면적인 구조일 수 있음을 시사. Qi et al. (2024)의 “shallow alignment” 주장과 일치.
한계점:
오직 refusal behavior만 분석. 실제 safety는 refusal 이상의 복잡한 행동을 포함.
Ablation이 다른 behavior에 미치는 부작용을 완전히 측정하지 못했을 수 있음 (refusal과 상관된 다른 desirable behavior 손실 가능성).
Open-source chat model에만 적용 가능. 모델 내부 접근(activation access) 필수.
Refusal direction이 단일이라는 주장이 모든 context에서 성립하는지는 불확실 (상황에 따라 다른 방향이 관여할 가능성).
후속 연구와의 연결:
COSMIC (ACL 2025)이 이 refusal direction을 multi-model로 일반화.
“Abliterated” 모델들이 Hugging Face에 700+개 공개 — 실질적 영향력 있는 jailbreak 방법이 됨.
IV. Summary
최종 요약 정리
이 논문의 핵심 기여:
Refusal = 단일 방향: 13개 모델에서 일관되게, refusal behavior가 residual stream의 1차원 subspace에 의해 매개됨을 실증.
양방향 제어: 이 방향을 ablate하면 refusal 제거, 추가하면 refusal 유도. Safety behavior의 on/off 스위치.
Surgical jailbreak: Directional ablation이 다른 capability를 최소한으로 손상하면서 refusal만 제거하는 novel한 white-box jailbreak.
Adversarial suffix의 메커니즘 설명: GCG 등이 이 refusal direction의 전파를 억제함으로써 작동.
우리 논문에 대한 시사점:
그들의 분석은 representation-level (어느 layer의 어느 방향), 우리는 logit-level temporal (어느 시점에서 어느 방향). 상호보완적.
우리의 temporal construct validity 실험에서 이 refusal direction과 ⁍의 cross-sample 상관을 측정: step 0에서 |r| 최대 0.62, 이후 약화. → ⁍가 이 refusal direction의 logit-level shadow일 수 있음을 시사.
그들이 “하나의 방향”이라고 주장하는 것에 대해, 우리는 “그 방향의 영향력이 디코딩 과정에서 시간에 따라 어떻게 변하는가”를 추가로 보여줌.
© Written by 2betforyou