
Towards Active Synthetic Data Generation for Fine-tuning Language Models, ICLR 2026

Reviewed:
I. Introduction
논문 Introduction 요약
Towards Active Synthetic Data Generation for Finetuning Language Models
세줄요약..
문제: LM을 훈련할 때 synthetic data를 생성하는데, 모든 데이터를 다 만드는 것, 한 번에 대량 생산하는 건 비효율적
해결방법: 모델이 못하는 부분(손실(불확실성)이 높은 것 = 어려운 문제)을 먼저 찾아서 그것만 집중적으로 생성하고, 반복 훈련
결과: 같은 성능을 내는데 필요한 데이터의 양을 크게 줄일 수 있음 (훈련 비용 절감)
Abstract
synthetic data를 학생 모델을 학습시키기 전에 미리 대량으로 생성하는 방식은 비효율적임
학생 모델의 현재 상태를 반영해 반복적으로 합성 데이터를 생성하자!
고정된 데이터 생성 예산에서 능동적 선택이 정적 생성보다 나은 학생 성능을 제공함
active learning의 단순한 선택 기준이 LLM-as-a-judge 같은 복잡한 LLM 전용 방법보다 더 효과적임
Introduction
대규모 언어 모델(LLM)은 강력하지만 비용이 높으므로, 소규모 언어 모델(SLM)을 교사 모델의 synthetic data로 파인튜닝하는 것이 실용적인 해결책임
언어 모델 학습은 보통 pre-trainig(사전학습) - supervised finetuning(SFT) - reinforcement learning from human feedback (RLHF) 또는 from verifiable rewards (RLVR) 의 단계로 이루어짐
SFT에 사용할 실제 데이터는 확보가 어렵거나 바람직한 특성이 부족할 수 있어 일반적으로는 더 강력한 모델을 사용해 질문-답변 쌍을 합성함
기존 방식: 한 번에 대량 생성, 종종 비효율적이며 많이 제거해도 성능 저하가 거의 없음
본 논문:
업데이트된 학생 모델을 다시 활용해 추가 데이터를 생성하는 반복 구조
active learning 알고리즘으로 우선순위가 매겨진 샘플을 기반으로 데이터를 생성
Preliminaries
Teacher 모델: (x,y) (질문, 답변 쌍) 생성
Student 모델: 해당 데이터로 SFT
생성 가능한 합성 샘플 수, 교사 모델 호출에 필요한 계산량을 고정된 예산이라고 가정
이 제약 하에서 제한된 synthetic data로 학생 모델 성능을 최대화하는 게 목표
손실 함수: 다음 토큰 예측의 교차엔트로피 손실 사용, SFT는 이 손실을 최소화하는 과정
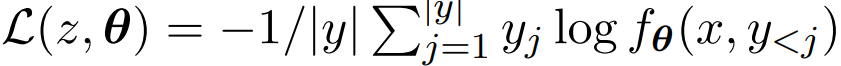
- 같은 샘플 수로 더 나은 성능을 달성하면 ‘더 효율적’
Related Work
- Distillation
교사 모델의 생성 답변(ŷ)으로 학생 모델을 훈련: (x, ŷ) 쌍 사용
SLM 학생 모델 성능 향상에 매우 효과적
- Synthetic question and answer generation
질문과 답변 모두 생성: ẑ = (x̂, ŷ)
작은 시드 데이터셋 크기에 제한 받지 않으면서 성능 향상을 가져옴
- Selective question and answer generation
- 대규모 정적 합성 데이터셋을 생성한 후 필터링하는 대신, synthetic 샘플 생성에 사용되는 시드 데이터를 신중하게 선별
- Active Learning
반복적으로 정보성 샘플을 식별하여 데이터 효율성을 극대화
model prediction disagreement
uncertainty
dataset summarization
predictive uncertainty와 sample diversity의 trade-off
- Data selection
Shapley value, influence function을 사용한 데이터 가치 추정
LLM을 사용해 데이터 점수 부여
training loss 또는 gradient norm 사용
reward 모델: 데이터 점수 부여 및 선택
Iterative Synthetic Data Generation
매 iteration마다 (t번 반복)
학생 모델로 시드 데이터에서 예측 생성
선택 알고리즘으로 데이터 부분집합(D̄ₜ) 선택
교사 모델로 선택된 데이터를 바탕으로 synthetic data 생성 (D̂ₜ)
학생 모델을 D̂ₜ ∪ D̂ₜ₋₁ 에서 재훈련
반복
선택 알고리즘:
- Uncertainty sampling
- 두 가지 loss가 있음
self-generation 기반 loss → 모델의 uncertainty proxy 반영
ground-truth 기반 loss
- 흥미롭게도, true loss 기반 접근이 uncertainty-based보다 덜 효과적임
- 두 가지 loss가 있음
- Reward scores
- 학생 모델이 생성한 응답 ŷ를 사용하여, 별도의 reward model로 학생 응답의 품질을 점수화함
- LLM-as-a-judge scores
별도의 reward model을 학습하는 대신, LLM을 프롬프트하여 학생 모델이 생성한 응답을 직접 평가하게 할 수 있음
LLM 판별자가 정답성, 유용성, 추론 품질 등 다양한 평가 기준을 반영할 수 있음
계산 비용이 크고 편향, 분산과 같은 추가적인 불확실성이 생김
- BADGE (Batch Active Learning by Diverse Gradient Embeddings)
- 불확실성과 다양성을 결합하여 데이터를 선택하는 방법
각 데이터 포인트에 대해 그래디언트 임베딩을 계산하고, 이를 k-means로 군집화함
각 클러스터의 중심에 해당하는 샘플 선택
- LM 환경에서는 이러한 임베딩 계산이 비용이 크고 확장성이 떨어짐
- 불확실성과 다양성을 결합하여 데이터를 선택하는 방법
Experiments
iterative protocol
- 매 iteration마다
비교 대상
random: 아무 기준 없이 질문 선택
lion: 쉬움/어려움 균형 샘플링
LLM-as-a-judge (hard): 어려운 샘플만 샘플링
loss (high): 손실(불확실성)이 큰 데이터를 우선순위로 지정