
Federated Balanced Learning, CVPR 2026
Reviewed:
I. Introduction
논문 Introduction 요약
https://arxiv.org/abs/2601.14042
Introduction
기존 연구들은 Non-IID를 최적화 단계(그래디언트/손실함수 수정)에서 문제를 해결하려 노력함 → Model drift 가 발생된 것을 교정하려는 시도, 근본적 문제(샘플의 불균형)을 해결하는 것이 아님
Diffusion model의 발전으로 스마트폰이나 라즈베리 파이에서도 작동
→ 따라서 클라이언트가 부족한 데이터를 생성하여 균형을 맞추는 능동적 참여자가 되어야함
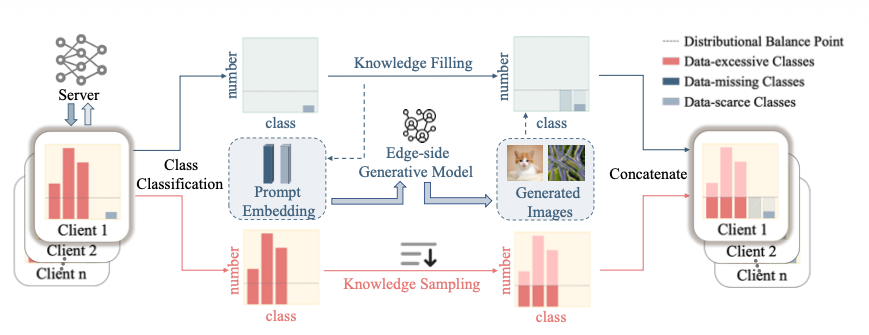
Federated Balanced Learning
클라이언트가 어떻게 샘플 균형을 맞추는가 각 데이터를 세가지로 분류
Data-excessive: 데이터가 너무 많은 클래스 → Knowledge sampling을 통해 데이터를 줄임
Data-scarce: 데이터가 부족한 클래스 → 생성모델로 채워넣음
Data-missing: 데이터가 아예 없는 클래스 → 생성모델로 채워넣음
생성한 데이터와 실제 데이터의 차이 극복
지식 정렬 전략
지식 드롭 전략
Related works
생성형 모델을 FL에 접목시키는 다른 연구들의 문제점 → 서버가 클라이언트의 레이블을 수집해야함
→ 사용자가 어떤 사진들을 가지고 있는지를 서버가 알 수 있게 되어 개인정보 침해의 소지가 있음
따라서, 프라이버시 문제 없이 FL에서 기존 edge-side 생성 모델을 통합하는 것이 필요
Methodology

1. Class Classification
계산 자원이 제한된 환경에서 샘플의 균형을 달성하기 위해 각 클라이언트 내의 모든 클래스별 샘플 수의 평균을 ‘분포 균형점’으로 지정함
분포 균형점(distributional balance point): ⁍
⁍: ⁍번째 클라이언트의 분포 균형점
⁍: 클래스의 수
⁍: 클래스에 속한 샘플의 수
분포 균형점 초과 → 데이터 과잉
분포 균형점 미만 → 데이터 부족
샘플 없음 → 데이터 결여
2. Knowledge Filling
데이터 부족/결여 클래스를 대상으로 Stable-Diffusion을 활용해 분포 균형점까지 데이터를 증강함
생성한 이미지와 실제 이미지의 도메인 겝을 해결하기 위한 두가지 전략
- 지식 정렬 전략
⁍
각 클래스에 학습 가능한 임베딩( ⁍ )을 만듦
특징 추출( ⁍ ): 생성된 이미지의 핵심 특징(프로토타입)을 뽑아냄
임베딩 더하기: 뽑아낸 프로토타입에 보정값(⁍)을 더해줌.
결과로 나온 벡터를 분류 해드( ⁍ )로 전달해 모델의 예측값을 생성함
- 지식 드롭 전략
⁍
보정값인 임베딩(⁍)이 특정 데이터에만 너무 과하게 맞춰지는 과적합(Overfitting) 현상을 방지하기 위해 도입됨
샘플중 일부를 무작위로 골라 임베딩을 더하지 않고 학습을 시킴
3. Knowledge Sampling
데이터 과잉 클래스에서 샘플 수를 분포 균형점까지 줄이는 방법 → 샘플을 줄여도 성능이 유사해야 함
- 손실 기반 지식 샘플링
각 샘플마다 학습에 영향을 미치는 정도가 다를 수 있음 → 손실값이 더 큰 샘플이 학습하기 더 적합한 데이터
⁍
손실 함수 값이 큰 순서대로 균형점만큼 샘플을 선택해야함
- 지식 리플레이
학습 단계에 따라 중요도가 달라짐, 새로운 데이터셋으로 학습될 때 이전 데이터를 잊어버리는 ‘파괴적 망각’이 일어남 → 다운샘플링으로 인한 지식 다양성 손실을 줄이기 위해 ⁍라운드 마다 지식 리플레이를 이용
전제 조건 연산: ⁍ 지식 리플레이: ⁍
4. Extended and Unified Framework
클라이언트가 계산이 제한된 상황과 무제한인 상황을 구분하여 Knowledge Filling 을 결정함
계산 제한 상황: 분포 균형점 → 샘플 수의 평균값
계산 무제한 상황: 분포 균형점 → 가장 큰 클래스의 샘플 수
계산 무제한 상황의 클라이언트 비율을 ⁍로 정의함
Experiments
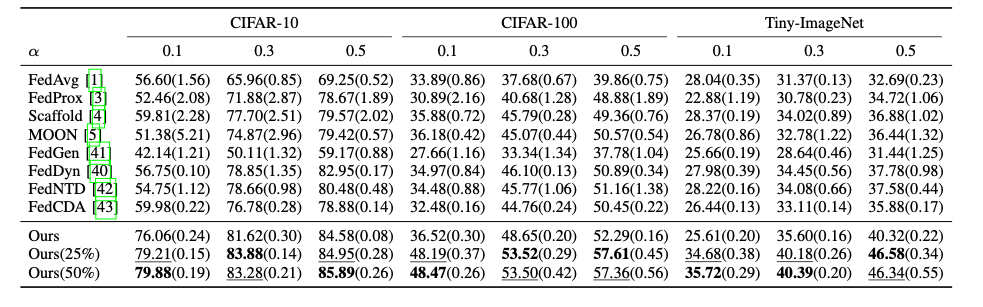
대부분의 상황에서 최고의 성능을 달성함
⁍가 커질수록 성능이 증가함 → 실제 상황에서 상황에 따라 ⁍를 증가하면 성능이 높아질 수 있음
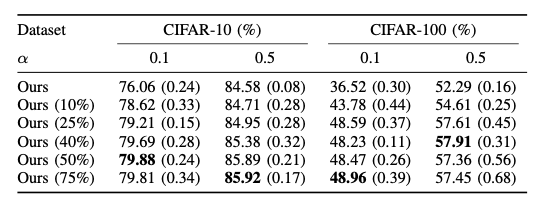
⁍에 상한선 존재 - 25% ~ 40%
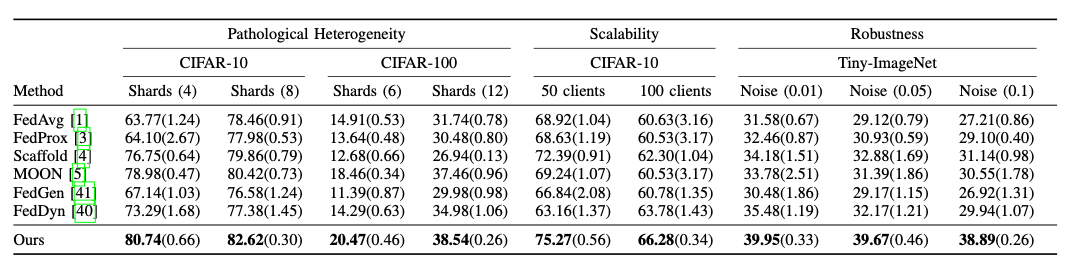
확장성 - 클라이언트가 50에서 100으로 늘어나도 가장 우수한 성능을 보여줌
강건함 - 가우시안 노이즈를 추가해 실험했을 때 다른 방법과 다르게 성능 저하가 거의 없음
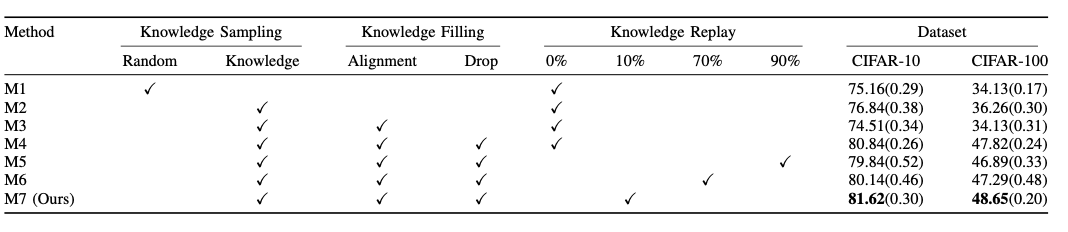
Knowledge sampling 에서 무작위로 샘플링하는 것이 아닌 손실 기반 지식 샘플링이 모두 성능이 높게 나타남
Knowledge Filling 에서 M2와 M3를 봤을때 지식 드롭 없이 지식 정렬만 하는 것은 오히려 악영향을 미침
지식 리플레이에서 이전 데이터 보존 비율을 10%로 했을 때 좋은 효과 → 적절한 균형점을 찾는 것이 중요
생성형 모델을 사용할 수 없는 초 저사양 기기들이 섞여있는 상황에서는 그러한 기기들만 FedAvg방식을 이용함
→ 전원 생성 가능한 상황과 성능 차이가 많이 나지 않음
Conclusion
Knowledge Sampling, Knowledge Filling을 통해 샘플 균형을 달성하는 FBL 제안
Knowledge Filling 단계에서는 생성된 데이터의 이질성을 극복하기 위한 ‘지식 정렬 전략’ ‘지식 드롭 전략’을 제시함
다양한 상황에서도 적용할 수 있도록 확장함
II. Proposed Method
사용한 / 제시된 기법, 알고리즘 등 요약
III. Results and Discussion
논문에 제시된 결과물 및 고찰을 요약