
Do Generated Data Always Help Contrastive Learning?, ICLR 2024
Reviewed:
코멘트 및 요약 인용 이유. Federated Balanced Learning에서 합성 데이터와 실제 데이터 간의 비율 또는 균형에 대한 탐색의 예시로 인용. 기존 연구 동향을 제시
https://arxiv.org/pdf/2403.12448
I. Introduction
논문 Introduction 요약
Contrastive Learning: 대조학습, 라벨이 없거나 적은 상황에서도 ‘비슷한 것은 가깝게, 다른 것은 멀게’ 표현공간을 학습하는 자기지도 학습(self-supervised learning)의 핵심 방법론.
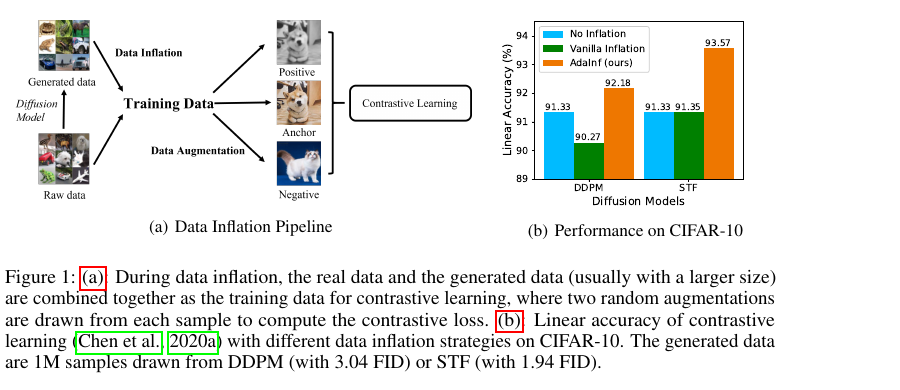
label이 없는 데이터셋이 주어졌을 때, 해당 데이터셋으로 생성 모델을 학습시켜 synthetic samples를 생성한 후, 실제 데이터와 생성된 데이터를 결합해 Contrastive Learning을 수행할 수 있음.
data infaltion: 생성 데이터를 새로운 독립 데이터로 취급. 그냉 샘플 수 증가(⁍)
data augmentation: 이미지가 원본이든 생성이든 상관없이 동일한 이미지에 대해, cropping, flipping, color jitter 등의 ‘수동 변환’을 가한 것.
- 증강의 목적: 같은 이미지에 서로 다른 변환 = positive pair 다른 이미지는 negative pair
data inflation은 학습에 ‘분포 변경’이라는 영향을 주고, data augmentation은 학습에 ‘표현 불변성’이라는 영향을 준다.
⇒ data inflation의 경우, 더 나은 생성 품질은 제한적인 도움이 되지만, real과 synthetic에 re-weighting(재가중치)를 부여하면 더 큰 이득을 볼 수 있음을 발견.
⇒ data augmentation의 경우, standard contrastive learning에서는 별론데, data inflation과 함께 사용될 때 유용할 수 있다는 것을 발견
⇒ data inflation을 위한 data augmentation 강도와 혼합 비율을 적응적으로 조절하는 Adaptive Inflation(AdaInf) 전략을 제안.
대충, 대조학습에서 데이터 재가중치와 약한 증강이 최종 성능 향상에 크게 기여함을 보임.
Self-Supervised Learning:
대조학습은,,, 각 샘플 ⁍에 대해, positive pair 로 두 개의 무작위로 증강된 sample ⁍를 추출함.
대조학습은 InfoNCE 손실에서 처럼 positive samples의 표현을 정렬하고, negative samples를 밀어내는게 목적임….
⁍
여기서 ⁍은 데이터 증강 ⁍을 사용해 ⁍에서 독립적으로 추출된 ⁍개의 negative samples임.
Generative Models:
많이 있지만, 논문에서는 Diffusion Model을 예로 듦.
학습시, 이미지 ⁍에 scale ⁍의 random Guassian Noise를 추가하고,
이미지 ⁍에 추가된 실제 노이즈를 재구성하기 위해 denoising network ⁍(일반적으로 U-net)을 학습시킴
i.e. ⁍
여기서 ⁍는 시간 ⁍에서의 혼합 계수임.
거기에, label이 없는 데이터에 대한 Contrastive Learning을 강화하기 위해 CIFAR-10으로 비지도 diffusion model을 학습.
Diffusion model로부터 100만개의 생성된 샘플들을 샘플링해서 실제 데이터에 추가함.
이 과정에서 train data = 5만 → 100만 이상으로 확장됨 ← 이게 data inflation
Data Inflation의 실패 원인 규명
DDPM(Denoising Diffusion Probabilistic Model) - 이건 표준적인 diffusion 기반 generative model의 원형임.
아무튼, DDPM으로 생성한 100만개의 이미지들을 직접 추가하는 것이 contrastive learning에 별로임.
⇒ inflation없는 baseline보다 성능이 낮음(linear accuracy) 91.33% → 90.27%
3.1 Data Inflation의 원인: 데이터 품질 및 데이터 재가중치
Fail이 Data Inflation 설계에 있는가?
실제 데이터 ⁍의 분포를 ⁍
생성 데이터 ⁍의 분포를 ⁍
inflation 후, 전체 분포는 ⁍가 됨. 여기서 ⁍는 두 데이터를 균등하게 혼합할 때 실제 데이터의 비율임.
실제 데이터와 생성 데이터 간의 분포 차이는 Theorem 3.1으로 특정지을 수 있음
Theorem 3.1 ⁍ where ⁍ denotes the TV distance
여기서 분포 차이에 영향을 주는건 생성된 데이터(의 분포) ⁍와 혼합 비율 ⁍임.
- Generated Data Quality:
실패의 이유는 DDPM의 성능이 구려서임.
다시 말하면, 생성모델이 완벽하지 않아서 **실제 데이터와 생성 데이터의 분포 차이가 커서 그럼. **
반대로 말하면, ⁍라면, 생성된 데이터는 (더 많은 training examples를 통해) 항상 도움이 될 것임.
⇒ 실제 데이터와의 차이를 검증하는 방법은? 생성 품질(FID)을 측정
근데 얘는 성능을 올리는게 좀 비쌈. 노력 대비 성능 개선이 크지 않음… 그래서 생성 모델을 STF로 고정하고, 다른 기법으로 성능을 개선할 계획.
- Data re-weighting:
Theorem 3.1을 보면, ⁍를 높이면(더 큰 혼합 비율을 사용하면) 실제 데이터의 가중치가 올라감(당연).
아무튼 그러면, ⁍의 차이를 줄일 수 있음. - 사실 이거도 당연함.
실제 구현은 real data를 ⁍번 복제해 가중치를 높임.
⇒ 최적 정확도 10:1(실제:생성) 정도임.
10을 넘기면 오히려 떨어짐 - 이는 복제 횟수로 인한 데이터 다양성 이점이 방해되기 때문.
3.2 Data Augmentation의 원인
서로 다른 Data augmentation 선택이 data inflation 의 성능에 어떻게 영향을 미칠까?
일반적으로 Random Resized Crop, RRC가 가장 중요하다 함.
그래서 최소 크롭된(상대적) 영역 크기, 즉 ⁍(⁍이 기본)를 반영해 증강 강도를 조절하고 나머지는 모두 고정함 ← ?
CIFAR-10, Half CIFAR-10(50% 무작위 분할), CIFAR-10 + 0.1M 생성 데이터(STF), CIFAR-10 + 1M 생성 데이터(STF) 네 개를 비교
⇒ 더 큰 학습데이터에 대해 일관되게 약한 데이터 증강을 쓰는게 좋다.
II. Proposed Method
사용한 / 제시된 기법, 알고리즘 등 요약
Adaptive Inflation, AdaInf
실제 데이터와 생성 데이터에 서로 다른 가중치를 부여해야 하며, 품질이 낮은 데이터는 더 낮은 가중치를 가져야 함.
더 많은 데이터와 함께 더 완화된 데이터 증강을 골라야 함.
⇒ AdaInf, 10:1의 실제:생성 데이터와 약한 증강.
이론적 특성화
4.1 수학
원본 데이터를 부분 그래프로 간주. 즉, 원본 데이터는 인플레이션 된 데이터의 무작위 부분집합으로 간주될 수 있음 ⁍: 인플레이션 된 데이터, ⁍: 증강된 데이터
…
아무튼 원본 데이터 ⁍를 ⁍의 무작위 부분집합으로 간주할 수 있음…
downstream(사전학습 후 실제로 쓰고싶은 구체 과제) 작업으로 linear probing(인코더는 고정, 그 위에 선형 분류기 하나만 붙여서 학습)을 사용해 학습된 feature 를 평가.
사전학습된 feature ⁍위에 가중치 ⁍(⁍은 클래스 수)를 가진 linear classifier ⁍로 학습해 증강된 데이터의 label ⁍를 예측함.
그 다음 실제 데이터를 예측하기 위한 다수결 분류기 ⁍를 정의함.
더 작은 분류 오류 ⁍는 더 나은 특징 분리도를 나타냄…
4.2 Inflated data에 대한 보장
Augmentation graph framework(이 그래프(데이터 증강이 훈련 샘플 간의 상호작용을 유도하는 그래프)의 스펙트럼 속성(라플라시안 행렬의 고유값 ⁍)을 통해 자기지도학습(대조학습)의 일반화 성능에 대한 이론적 보장을 제공한 논문임)를 핵심 이론으로, 이 결과와 비교해 사전 학습과 downstream에서 분포간의 불일치(즉, ODD 일반화)를 수용함..
Theorem 4.1 확률 ⁍이상으로, inflated 데이터에 대한 최적 encoder ⁍와 학습된 선형 헤드 ⁍에 대해, linear probing error 는 다음과 같은 상한을 갖는다:
여기서 ⁍는 데이터 증강으로 인한 라벨링 오류
⁍은 라플라시안 행렬 ⁍의 ⁍째 작은 고유값. ⁍는 실제 데이터와 생성 데이터 간의 total variation(TV)임.
⇒ 이는 더. ㅏ은 생성 모델(낮은 FID)을 활용하는 것이 왜 일관되게 더 나은 downstream 성능을 가져오는지 자연스럽게 설명.
마찬가지로, 원본 데이터의 더 큰 가중치 ⁍또한 분포 차이를 좁히는데 도움됨.
labelling error ⁍에 미치는 영향은 직관적으로 증강이 다른 클래스에 속하는 샘플을 생성할 확률을 의미함.
더 강력한 증강(더 큰 크롭)은 종종 더 큰 라벨링 오류로 이어짐. ⁍는 기댓값으로 계산되므로, inflated data는 ⁍에 영향을 주지 않음…
검증 실험: labelling error ⁍와 연결성 ⁍의 영향을 실험할거임.
설정:
평균이 (-1,0) 및 (1,0)인 등방성 Gaussian Distribution(two-classes)와 분산 0.7에서 데이터를 샘플링.
증강은 번지름 ⁍인 원 안에서 균일한 노이즈를 적용 - 즉, ⁍은 증강 강도의 척도임.
결과:
1) 큰 데이터 크기와 더 강한 증강이 실제로 상호 보완적임 - 둘 다 더 나은 연결성(⁍ 상승)을 가져옴
2) 더 강한 증강이 더 큰 labelling error ⁍를 가져옴
3) 결합되었을 때 최적의 증강이 데이터 크기 증가시 작아짐 - 증강 최적은 데이터 크기가 커질 때 작은 증강임