
Balancing Cost and Effectiveness of Synthetic Data Generation Strategies for LLMs, NeurIPS ‘24 Workshop on Fine-Tuning in Modern Machine Learning: Principles and Scalability
Reviewed:
I. Introduction
논문 Introduction 요약
Balancing Cost and Effectiveness of Synthetic Data Generation…
Abstract
LLM 활용 사례가 증가하면서, 파인튜닝을 위한 고품질, task-specific 데이터셋을 만드는 것이 모델 성능 향상에 있어 중요한 과제로 부상함
고품질 human data: 비쌈
synthetic data: 자원이 제한된 환경이나 검증하기 어려운 작업에서 효과가 불분명함
최적의 전략은 teacher query budget과 seed instruction set 크기의 비율에 따라 크게 좌우됨
Introduction
현실의 실무자들은 제한된 예산 속에서 어떤 데이터 생성 방식을 선택해야 할지 명확한 가이드가 없는 상황
목표: 제한된 시드 데이터로 학생 모델 성능을 최대화하기
데이터 제약 하 합성 전략 비교 프레임워크 제안
BR(Q/S)에 따른 최적 전략 변화 규명
New Question에서 augmentation 모델 성능이 중요함을 발견
Method
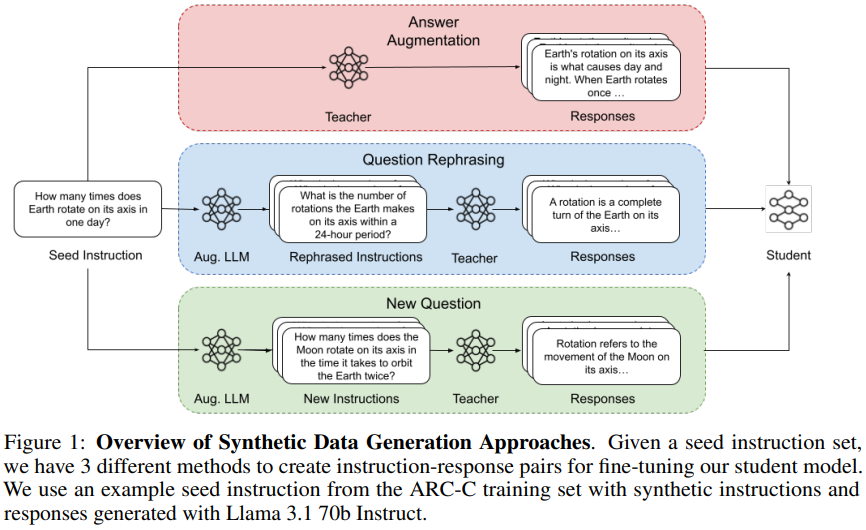
학생 모델은 STF(지도 학습) 방식으로 학습되며, instruction-response 쌍이 필요함
STF에 적합한 synthetic data 생성 전략을 세 가지로 구분

- Answer Augmentaion
같은 질문에 대해 다양한 답변(추론 경로, 표현)을 생성
질문 수 = 시드 수
가장 저렴
- Question Rephrasing
기존 질문과 의미는 같게, 표현만 바꾼 질문을 생성
Answer Augmentaion보다 어려움
기존 답변 재사용 가능 → 비용 효율적
- New Question
기존 질문을 기반으로 완전히 새로운 질문(정답도 다름)을 생성
Question Rephrasing보다 도메인 다양성이 큼
비용은 높음
- Answer Augmentaion
Experimental Setup
Teacher - Augmenter - Student
접근 방식의 범용성을 평가하기 위해 수학, 코딩, 일반 QA 세 가지 과제를 선택
교사와 증강 모델은 Llama 3.1 70B, 학생 모델은 Llama 2 7B Chat을 사용 → 교사와 학생 간 성능 격차를 크게 만들어 합성 데이터 전략의 효과를 명확히 보기 위함
데이터셋 크기를 ‘100’, ‘1000’, ‘전체’로 나눔
BR(Query Budget / Seed Size)이 클수록 시드 대비 synthetic data가 많음을 의미함
Seed Size: 초기 데이터
Query budget: 쿼리 수, 합성 데이터 양
Budget Ratio (BR)
Experimental Results
- Effectiveness of Synthetic Data Generation Strategies
같은 비용(Q)으로 만들었을 때, 어떤 전략이 ‘더 좋은 데이터’를 만들어 주는가?
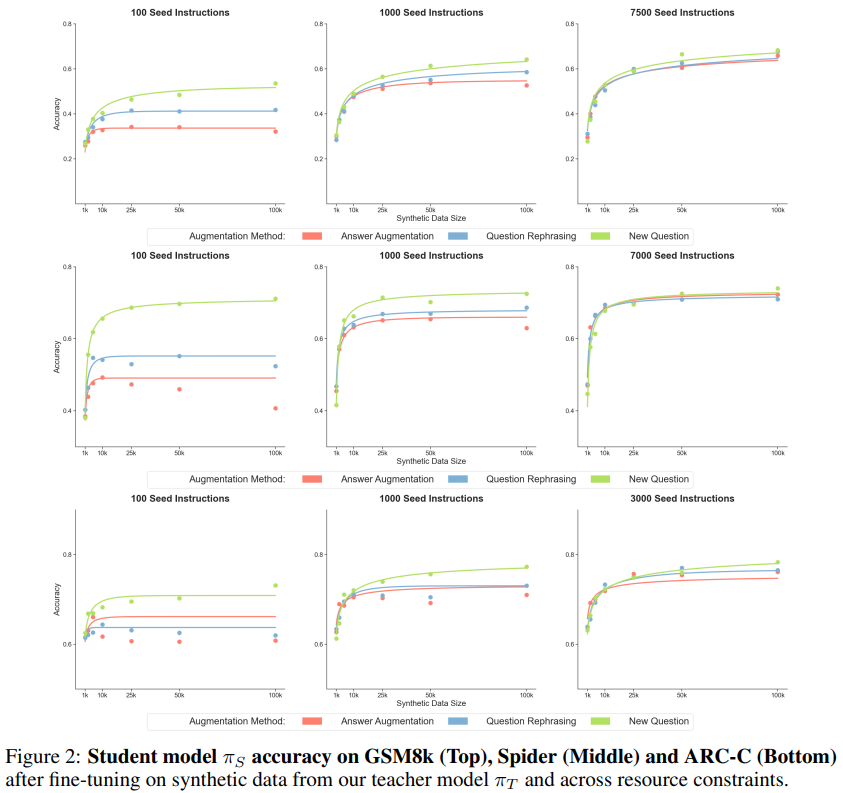
결과 해석
- Seed = 100 | Rewrite | New Question | | | — | — | — | | 초반 급상승 | 특징 | 초반 느림 | | 10k~25k 부근에서 성능 정체 | 50k~100k에서도 계속 증가 | | | 기존 seed의 support 안에서만 샘플링 | 왜? | support 확장 | | 다양성 빠르게 고갈됨 | distribution coverage 증가 | |
⇒ 초기 데이터가 적을 때는 어떤 전략을 선택하는지가 중요하지만, 초기 데이터가 충분하면 각 방법 간 성능 차이가 줄어듦
- Seed = 1000
- 전체적으로 성능 격차 감소
Rewrite의 포화 시점이 늦어짐
New Question이 여전히 우세하나 차이는 줄어듦
⇒ Seed가 늘수록 synthetic data의 ‘정보 밀도’ 감소
- Full Seed
- 모든 전략 간 성능 차이 거의 없음
- synthetic data의 역할 자체가 줄어듦
⇒ 이미 분포를 잘 알고 있음 → 추가 생성 이득 ↓
- New Question이 가장 scalable (100개의 시드 명령어를 사용한 GSM8k 실험에서, 데이터셋을 50,000개 이상의 예시(초기 크기의 500배 이상)로 확장할 때 다른 생성 방법들이 정체되는 반면, New Question 전략은 정확도를 지속적으로 향상시킵니다.)
- Cost-Effectiveness of Synthetic Data Generation
성능이 올라가긴 하는데… 어디까지가 ‘가성비’인가?
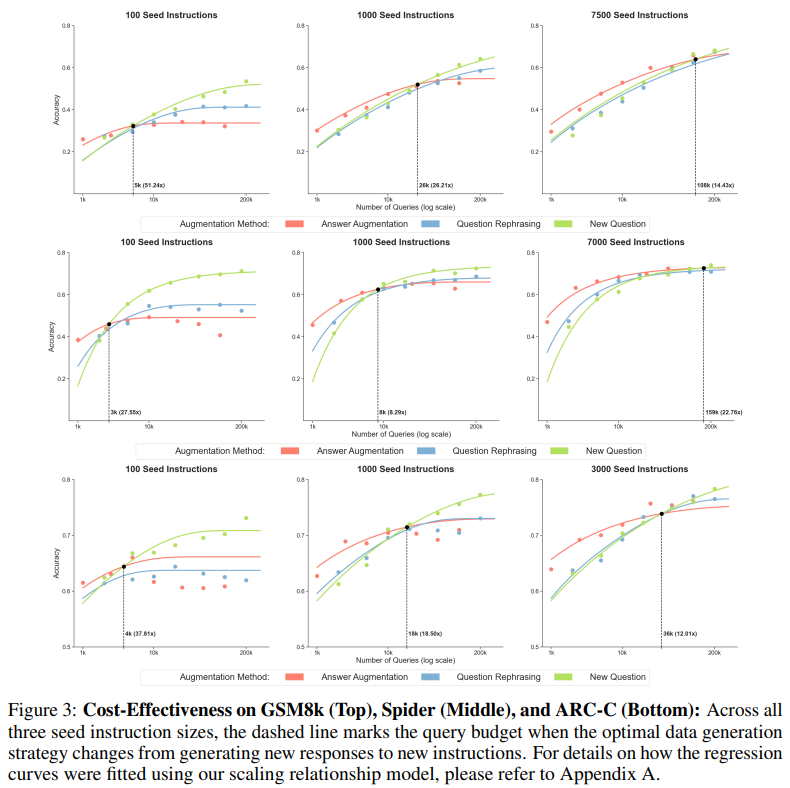
결과 해석
BR이 낮을 때(예산이 적을때): Answer Augmentation(같은 질문으로 여러 답변 만들기)이 최고
BR이 높을 때(예산이 충분할 때): New Question 생성이 최고
New Question이 더 좋지만, Question Rephrase는 구현이 쉬워서 제약이 있는 상황에선 더 잘 맞을 수 있음
⇒ 최적 전략은 하나가 아니다!!!
LLM 훈련을 위한 최적의 data augmentaion 전략을 결정할 때 초기 데이터셋 크기와 사용 가능한 예산을 모두 고려하는 것이 중요
모든 예산 구간에서 항상 우수한 전략은 없음
Ablation Studies
결론의 일반성 확보
Augmentation Model이 달라져도 실험 결과는 같은가?
synthetic response가 정답인지 검증하는 것이 synthetic 데이터셋의 효과성을 높이는가?
Student Model이 달라져도 비율 효율성 결과가 유지되는가?
Conclusion
본 논문은 다양한 리소스 제약 하에서 합성 데이터 전략을 선택하는 프레임워크를 제시함
최적 전략은 쿼리 예산과 시드 명령어 세트 크기의 비율에 따라 달라짐
데이터가 풍부한 환경에서는 증강 전략 선택이 덜 중요해짐
질문 재구성(Rephrasing)은 성능이 낮은 증강 모델에서도 견고하게 작동함
synthetic response 검증과 학생 모델 선택은 상대적으로 영향력 ↓
II. Proposed Method
사용한 / 제시된 기법, 알고리즘 등 요약
III. Results and Discussion
논문에 제시된 결과물 및 고찰을 요약